\n
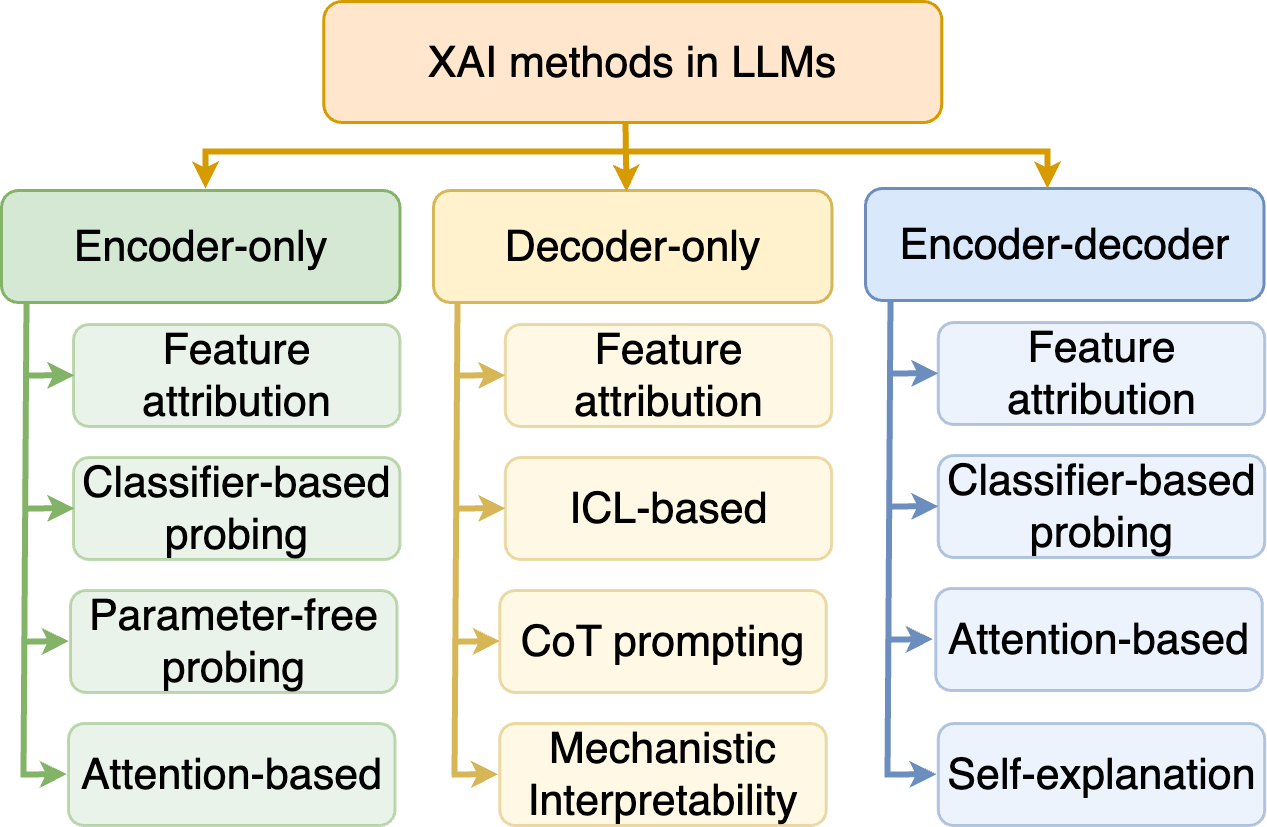
## Diagram: XAI Methods in LLMs
### Overview
This diagram illustrates the categorization of Explainable AI (XAI) methods applied to Large Language Models (LLMs). The methods are categorized based on the underlying LLM architecture: Encoder-only, Decoder-only, and Encoder-decoder. Each architecture then branches into several specific XAI techniques. Arrows indicate relationships and flow between categories.
### Components/Axes
* **Header:** "XAI methods in LLMs" (centered, top)
* **Main Categories (Vertical Blocks):**
* Encoder-only (left)
* Decoder-only (center)
* Encoder-decoder (right)
* **Sub-categories (Rectangles within each block):**
* **Encoder-only:** Feature attribution, Classifier-based probing, Parameter-free probing, Attention-based
* **Decoder-only:** Feature attribution, ICL-based, CoT prompting, Mechanistic Interpretability
* **Encoder-decoder:** Feature attribution, Classifier-based probing, Attention-based, Self-explanation
* **Arrows:** Indicate flow and relationships between categories. Arrows originate from the header and point to the main categories, and also connect sub-categories within each main category.
### Detailed Analysis or Content Details
The diagram presents a hierarchical structure.
1. **XAI methods in LLMs (Header):** This is the overarching topic.
2. **Encoder-only:**
* Arrows flow from the header to "Encoder-only".
* Sub-categories:
* "Feature attribution"
* "Classifier-based probing"
* "Parameter-free probing"
* "Attention-based"
3. **Decoder-only:**
* Arrows flow from the header to "Decoder-only".
* Sub-categories:
* "Feature attribution"
* "ICL-based" (In-Context Learning-based)
* "CoT prompting" (Chain-of-Thought prompting)
* "Mechanistic Interpretability"
4. **Encoder-decoder:**
* Arrows flow from the header to "Encoder-decoder".
* Sub-categories:
* "Feature attribution"
* "Classifier-based probing"
* "Attention-based"
* "Self-explanation"
The arrows connecting the sub-categories within each main category suggest that these techniques can be applied or are related to each other within that specific LLM architecture.
### Key Observations
* "Feature attribution" appears as a common XAI method across all three LLM architectures.
* "Attention-based" methods are present in both Encoder-only and Encoder-decoder architectures.
* "Classifier-based probing" is present in both Encoder-only and Encoder-decoder architectures.
* The Decoder-only architecture has unique methods like "ICL-based", "CoT prompting", and "Mechanistic Interpretability".
### Interpretation
The diagram demonstrates a structured approach to categorizing XAI methods based on the underlying LLM architecture. This suggests that the choice of XAI technique may depend on the specific type of LLM being used. The presence of common methods like "Feature attribution" across all architectures indicates their general applicability. The unique methods within the Decoder-only category highlight the specific challenges and opportunities associated with explaining the behavior of decoder-based LLMs. The diagram is a high-level overview and doesn't provide details on the implementation or effectiveness of each method. It serves as a useful framework for understanding the landscape of XAI in LLMs.