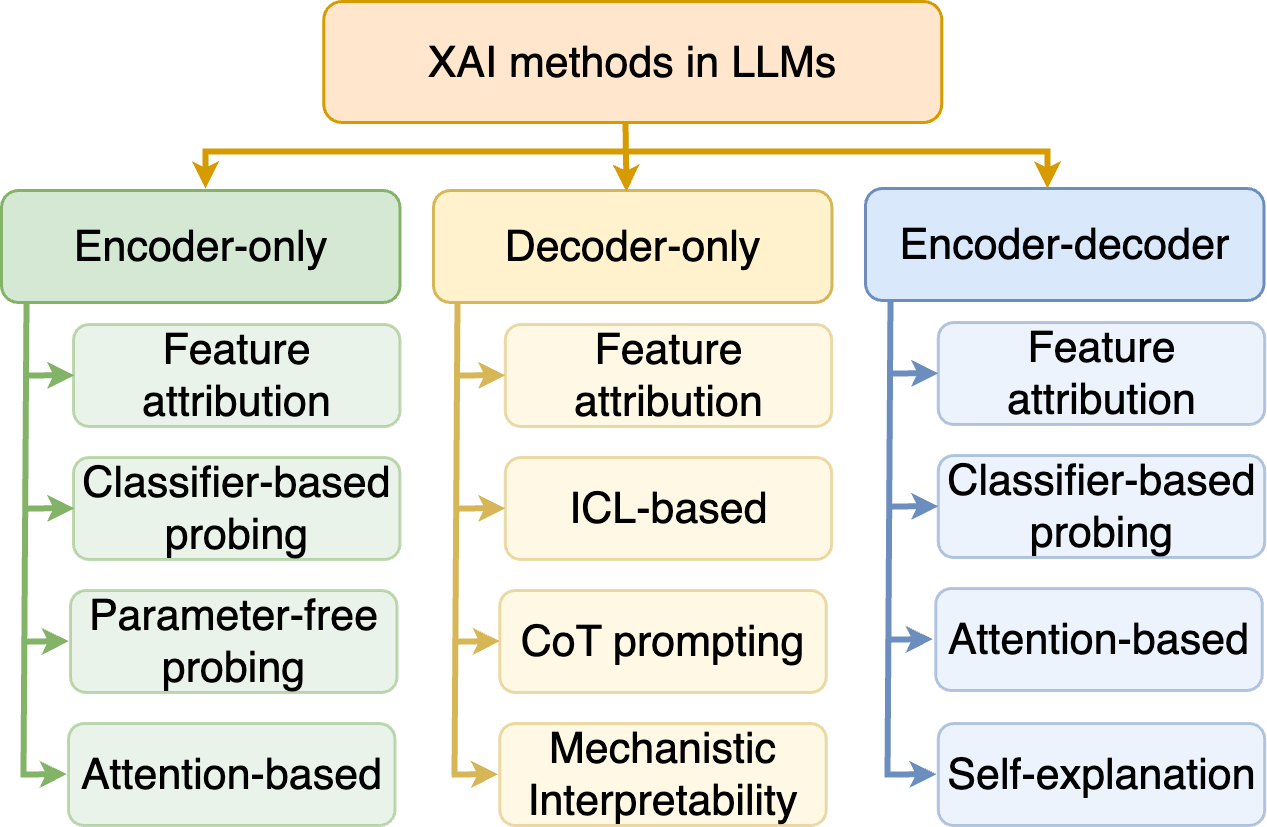
## Diagram: XAI Methods in LLMs
### Overview
The diagram categorizes Explainable AI (XAI) methods used in Large Language Models (LLMs) into three hierarchical groups: **Encoder-only**, **Decoder-only**, and **Encoder-decoder**. Each group contains subcategories representing specific XAI techniques, connected via directional arrows.
### Components/Axes
- **Main Title**: "XAI methods in LLMs" (top-center, orange background).
- **Three Primary Branches**:
1. **Encoder-only** (green background, left).
2. **Decoder-only** (orange background, center).
3. **Encoder-decoder** (blue background, right).
- **Subcategories**:
- **Encoder-only**:
- Feature attribution
- Classifier-based probing
- Parameter-free probing
- Attention-based
- **Decoder-only**:
- Feature attribution
- ICL-based
- CoT prompting
- Mechanistic Interpretability
- **Encoder-decoder**:
- Feature attribution
- Classifier-based probing
- Attention-based
- Self-explanation
### Detailed Analysis
- **Color Coding**:
- Encoder-only: Green (#98FB98).
- Decoder-only: Orange (#FFE4B5).
- Encoder-decoder: Blue (#ADD8E6).
- **Flow Direction**: Arrows point from main branches to subcategories, indicating hierarchical relationships.
- **Text Placement**: All labels are left-aligned within rectangular boxes, with arrows connecting parent and child nodes.
### Key Observations
1. **Feature attribution** appears in all three branches, suggesting its universal applicability.
2. **Classifier-based probing** is used in both Encoder-only and Encoder-decoder frameworks.
3. **Attention-based** methods are present in Encoder-only and Encoder-decoder but absent in Decoder-only.
4. **Decoder-only** methods emphasize **ICL-based** and **CoT prompting**, which are unique to this category.
5. **Self-explanation** is exclusive to the Encoder-decoder framework.
### Interpretation
The diagram illustrates how XAI methods in LLMs are stratified by their reliance on encoder, decoder, or both components.
- **Encoder-centric methods** (green) focus on probing and attention mechanisms, likely analyzing input representations.
- **Decoder-centric methods** (orange) prioritize in-context learning (ICL) and chain-of-thought (CoT) prompting, which are critical for output generation.
- **Encoder-decoder methods** (blue) combine probing, attention, and self-explanation, reflecting a holistic approach to interpretability across both input and output processing.
Notably, **self-explanation** and **mechanistic interpretability** are unique to their respective branches, highlighting specialized techniques for complex model architectures. The absence of **attention-based** methods in the Decoder-only category suggests decoder-specific challenges in leveraging attention for interpretability.
This categorization aids researchers in selecting XAI strategies aligned with their model’s architecture and interpretability goals.