## Scatter Plots: Model Performance vs. Cost
### Overview
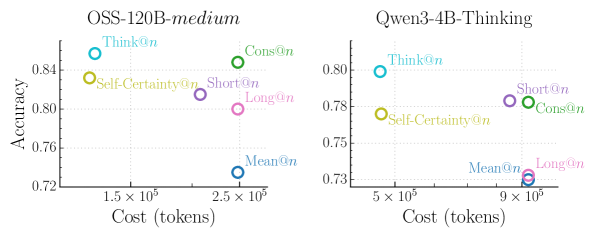
The image contains two side-by-side scatter plots comparing model performance (accuracy) against computational cost (tokens) for two AI systems: **OSS-120B-medium** (left) and **Qwen3-4B-Thinking** (right). Each plot uses color-coded data points to represent different evaluation metrics or strategies, with labels like "Think@n" and "Self-Certainty@n".
---
### Components/Axes
- **X-axis**: Cost (tokens), logarithmic scale (1.5×10⁵ to 9×10⁵ tokens).
- **Y-axis**: Accuracy (0.72 to 0.85 range).
- **Legends**:
- **OSS-120B-medium**: Blue (Think@n), Green (Cons@n), Purple (Short@n), Pink (Long@n), Yellow (Self-Certainty@n), Cyan (Mean@n).
- **Qwen3-4B-Thinking**: Same color scheme as above.
- **Data Points**: Each point is labeled with its metric (e.g., "Think@n") and positioned at specific (cost, accuracy) coordinates.
---
### Detailed Analysis
#### OSS-120B-medium (Left Plot)
- **Think@n**: Highest accuracy (0.85) at lowest cost (1.5×10⁵ tokens).
- **Cons@n**: Second-highest accuracy (0.84) at moderate cost (2.2×10⁵ tokens).
- **Self-Certainty@n**: Accuracy 0.83 at 2×10⁵ tokens.
- **Short@n**: Accuracy 0.79 at 2.5×10⁵ tokens.
- **Long@n**: Accuracy 0.78 at 3×10⁵ tokens.
- **Mean@n**: Lowest accuracy (0.76) at 2.8×10⁵ tokens.
#### Qwen3-4B-Thinking (Right Plot)
- **Cons@n**: Highest accuracy (0.79) at 6.5×10⁵ tokens.
- **Think@n**: Accuracy 0.80 at 5×10⁵ tokens.
- **Self-Certainty@n**: Accuracy 0.78 at 6×10⁵ tokens.
- **Short@n**: Accuracy 0.77 at 7×10⁵ tokens.
- **Long@n**: Accuracy 0.76 at 8×10⁵ tokens.
- **Mean@n**: Lowest accuracy (0.75) at 7.5×10⁵ tokens.
---
### Key Observations
1. **Cost-Accuracy Tradeoff**:
- OSS-120B-medium achieves higher accuracy (0.76–0.85) at significantly lower costs (1.5–3×10⁵ tokens) compared to Qwen3-4B-Thinking (5–8×10⁵ tokens).
- Qwen3-4B-Thinking shows diminishing returns: higher costs correlate with lower accuracy (e.g., Long@n at 8×10⁵ tokens has 0.76 accuracy).
2. **Performance Variability**:
- "Mean@n" points (likely average performance) are consistently the lowest in accuracy for both models, suggesting heterogeneity in individual metric performance.
3. **Efficiency**:
- OSS-120B-medium’s "Think@n" and "Cons@n" strategies outperform Qwen3-4B-Thinking’s equivalents despite lower computational costs.
---
### Interpretation
The data highlights **OSS-120B-medium** as a more cost-effective solution for high-accuracy tasks, with its top-performing strategies ("Think@n", "Cons@n") achieving near-peak accuracy at minimal token expenditure. In contrast, **Qwen3-4B-Thinking** exhibits inefficiency, with higher costs yielding only marginal accuracy gains. The "Mean@n" points underscore systemic underperformance in average configurations, suggesting that optimal strategies (e.g., "Think@n") require deliberate design rather than default settings. These findings imply that model architecture and strategy selection are critical for balancing accuracy and resource efficiency in AI systems.