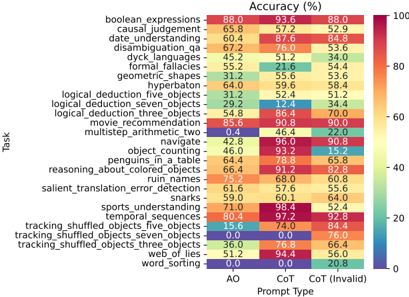
## Heatmap: Task Accuracy vs. Prompt Type
### Overview
The image is a heatmap displaying the accuracy (in percentage) of different tasks when using different prompt types: AO, CoT, and CoT (Invalid). The tasks are listed on the vertical axis, and the prompt types are listed on the horizontal axis. The color intensity represents the accuracy percentage, with red indicating high accuracy and blue indicating low accuracy.
### Components/Axes
* **Title:** Accuracy (%)
* **X-Axis Title:** Prompt Type
* **X-Axis Labels:** AO, CoT, CoT (Invalid)
* **Y-Axis Title:** Task
* **Y-Axis Labels:** boolean\_expressions, causal\_judgement, date\_understanding, disambiguation\_qa, dyck\_languages, formal\_fallacies, geometric\_shapes, hyperbaton, logical\_deduction\_five\_objects, logical\_deduction\_seven\_objects, logical\_deduction\_three\_objects, movie\_recommendation, multistep\_arithmetic\_two, navigate, object\_counting, penguins\_in\_a\_table, reasoning\_about\_colored\_objects, ruin\_names, salient\_translation\_error\_detection, snarks, sports\_understanding, temporal\_sequences, tracking\_shuffled\_objects\_five\_objects, tracking\_shuffled\_objects\_seven\_objects, tracking\_shuffled\_objects\_three\_objects, web\_of\_lies, word\_sorting
* **Colorbar (Right Side):**
* 100 (Red)
* 80
* 60
* 40
* 20
* 0 (Blue)
### Detailed Analysis
Here's a breakdown of the accuracy for each task across the different prompt types:
* **boolean\_expressions:** AO: 88.0%, CoT: 93.6%, CoT (Invalid): 52.9%
* **causal\_judgement:** AO: 65.8%, CoT: 57.2%, CoT (Invalid): 52.9%
* **date\_understanding:** AO: 60.4%, CoT: 87.6%, CoT (Invalid): 84.8%
* **disambiguation\_qa:** AO: 67.2%, CoT: 76.0%, CoT (Invalid): 53.6%
* **dyck\_languages:** AO: 45.2%, CoT: 51.2%, CoT (Invalid): 34.0%
* **formal\_fallacies:** AO: 55.2%, CoT: 21.6%, CoT (Invalid): 54.4%
* **geometric\_shapes:** AO: 31.2%, CoT: 55.6%, CoT (Invalid): 53.6%
* **hyperbaton:** AO: 64.0%, CoT: 59.6%, CoT (Invalid): 58.4%
* **logical\_deduction\_five\_objects:** AO: 31.2%, CoT: 52.4%, CoT (Invalid): 51.2%
* **logical\_deduction\_seven\_objects:** AO: 29.2%, CoT: 12.4%, CoT (Invalid): 34.4%
* **logical\_deduction\_three\_objects:** AO: 54.8%, CoT: 86.4%, CoT (Invalid): 70.0%
* **movie\_recommendation:** AO: 85.6%, CoT: 90.8%, CoT (Invalid): 90.0%
* **multistep\_arithmetic\_two:** AO: 0.4%, CoT: 46.4%, CoT (Invalid): 22.0%
* **navigate:** AO: 42.8%, CoT: 96.0%, CoT (Invalid): 90.8%
* **object\_counting:** AO: 46.0%, CoT: 93.2%, CoT (Invalid): 15.2%
* **penguins\_in\_a\_table:** AO: 64.4%, CoT: 78.8%, CoT (Invalid): 65.8%
* **reasoning\_about\_colored\_objects:** AO: 66.4%, CoT: 91.2%, CoT (Invalid): 82.8%
* **ruin\_names:** AO: 75.2%, CoT: 68.0%, CoT (Invalid): 60.8%
* **salient\_translation\_error\_detection:** AO: 61.6%, CoT: 57.6%, CoT (Invalid): 55.6%
* **snarks:** AO: 59.0%, CoT: 60.1%, CoT (Invalid): 64.0%
* **sports\_understanding:** AO: 71.0%, CoT: 98.4%, CoT (Invalid): 52.4%
* **temporal\_sequences:** AO: 80.4%, CoT: 97.2%, CoT (Invalid): 92.8%
* **tracking\_shuffled\_objects\_five\_objects:** AO: 15.6%, CoT: 74.0%, CoT (Invalid): 84.4%
* **tracking\_shuffled\_objects\_seven\_objects:** AO: 0.0%, CoT: 0.0%, CoT (Invalid): 76.0%
* **tracking\_shuffled\_objects\_three\_objects:** AO: 36.0%, CoT: 76.8%, CoT (Invalid): 66.4%
* **web\_of\_lies:** AO: 51.2%, CoT: 94.4%, CoT (Invalid): 56.0%
* **word\_sorting:** AO: 0.0%, CoT: 0.0%, CoT (Invalid): 20.8%
### Key Observations
* **CoT (Chain of Thought) Prompting generally improves accuracy:** For most tasks, the CoT prompt type (both valid and invalid) yields higher accuracy compared to the AO prompt type.
* **Multistep Arithmetic is uniquely bad with AO:** The "multistep\_arithmetic\_two" task has extremely low accuracy with the AO prompt (0.4%), but improves significantly with CoT (46.4%) and CoT (Invalid) (22.0%).
* **Tracking Shuffled Objects is uniquely bad with AO and CoT:** The "tracking\_shuffled\_objects\_seven\_objects" task has 0.0% accuracy with both AO and CoT, but improves significantly with CoT (Invalid) (76.0%).
* **CoT (Invalid) can sometimes outperform CoT:** In some cases, the "CoT (Invalid)" prompt performs better than the "CoT" prompt, suggesting that even flawed reasoning chains can be beneficial.
* **Some tasks are consistently high-performing:** "movie\_recommendation" and "temporal\_sequences" consistently show high accuracy across all prompt types.
### Interpretation
The heatmap illustrates the impact of different prompting strategies on the accuracy of various tasks. The Chain of Thought (CoT) prompting method generally enhances performance, likely by enabling the model to break down complex problems into smaller, more manageable steps. However, the "CoT (Invalid)" results suggest that even imperfect reasoning chains can lead to improved outcomes compared to direct prompting (AO).
The significant accuracy boost observed for "multistep\_arithmetic\_two" and "tracking\_shuffled\_objects\_seven\_objects" with CoT prompting highlights the importance of structured reasoning for tasks that require multiple steps or complex logic. The fact that "CoT (Invalid)" sometimes outperforms "CoT" indicates that the mere presence of a reasoning chain, even if flawed, can be more beneficial than no reasoning at all.
The consistent high performance of tasks like "movie\_recommendation" and "temporal\_sequences" suggests that these tasks are inherently easier for the model, regardless of the prompting strategy used. Conversely, tasks like "dyck\_languages" and "logical\_deduction\_seven\_objects" remain challenging even with CoT prompting, indicating a need for more sophisticated approaches.