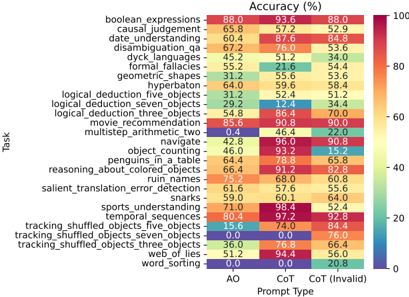
## Heatmap: Task Accuracy by Prompt Type
### Overview
This heatmap compares the accuracy (%) of various AI tasks across three prompt types: AO (Answer Only), CoT (Chain of Thought), and CoT Invalid. Tasks range from logical reasoning to language understanding, with color intensity indicating performance (blue = low, red = high).
### Components/Axes
- **Y-Axis (Tasks)**: 25 tasks including:
- boolean_expressions, causal_judgement, date_understanding, disambiguation_qa, dyck_languages, formal_fallacies, geometric_shapes, hyperbaton, logical_deduction_five_objects, logical_deduction_seven_objects, logical_deduction_three_objects, movie_recommendation, multistep_arithmetic_two, navigate, object_counting, penguins_in_a_table, reasoning_about_colored_objects, ruin_names, salient_translation_error_detection, sharks, sports_understanding, temporal_sequences, tracking_shuffled_objects_five_objects, tracking_shuffled_objects_seven_objects, tracking_shuffled_objects_three_objects, web_of_lies, word_sorting.
- **X-Axis (Prompt Types)**: AO, CoT, CoT Invalid.
- **Legend**: Color gradient from blue (0%) to red (100%), with labeled thresholds (e.g., 20%, 40%, 60%, 80%, 100%).
### Detailed Analysis
- **AO Column**:
- Highest accuracy: sports_understanding (71.0%), tracking_shuffled_objects_three_objects (36.0%).
- Lowest accuracy: geometric_shapes (31.2%), word_sorting (0.0%).
- **CoT Column**:
- Highest accuracy: sports_understanding (98.4%), tracking_shuffled_objects_three_objects (76.8%).
- Lowest accuracy: geometric_shapes (55.6%), word_sorting (0.0%).
- **CoT Invalid Column**:
- Highest accuracy: sports_understanding (52.4%), tracking_shuffled_objects_three_objects (66.4%).
- Lowest accuracy: geometric_shapes (53.6%), word_sorting (20.8%).
### Key Observations
1. **CoT Dominance**: CoT generally outperforms AO and CoT Invalid across most tasks (e.g., boolean_expressions: 93.6% vs. 88.0% AO).
2. **CoT Invalid Anomalies**:
- Some tasks degrade under CoT Invalid (e.g., geometric_shapes: 53.6% vs. 55.6% CoT).
- Others improve (e.g., tracking_shuffled_objects_three_objects: 66.4% vs. 76.8% CoT).
3. **Zero Performance**: word_sorting fails entirely under AO and CoT (0.0%).
4. **Color Consistency**: Red hues dominate CoT, while blue hues cluster in CoT Invalid for tasks like geometric_shapes.
### Interpretation
The data suggests **CoT prompting enhances performance** for complex reasoning tasks (e.g., logical_deduction, sports_understanding), likely due to its structured reasoning process. However, **CoT Invalid introduces variability**:
- **Degradation**: Tasks requiring precise logic (geometric_shapes, word_sorting) suffer under CoT Invalid, possibly due to invalid intermediate steps.
- **Improvement**: Tasks with spatial/temporal reasoning (tracking_shuffled_objects) benefit from CoT Invalid, hinting at robustness to partial reasoning.
Notable outliers include **sports_understanding** (consistently high) and **word_sorting** (consistently low), indicating task-specific model biases. The heatmap underscores the importance of prompt design for task alignment.