## System Diagram: Fallacy Type Classification
### Overview
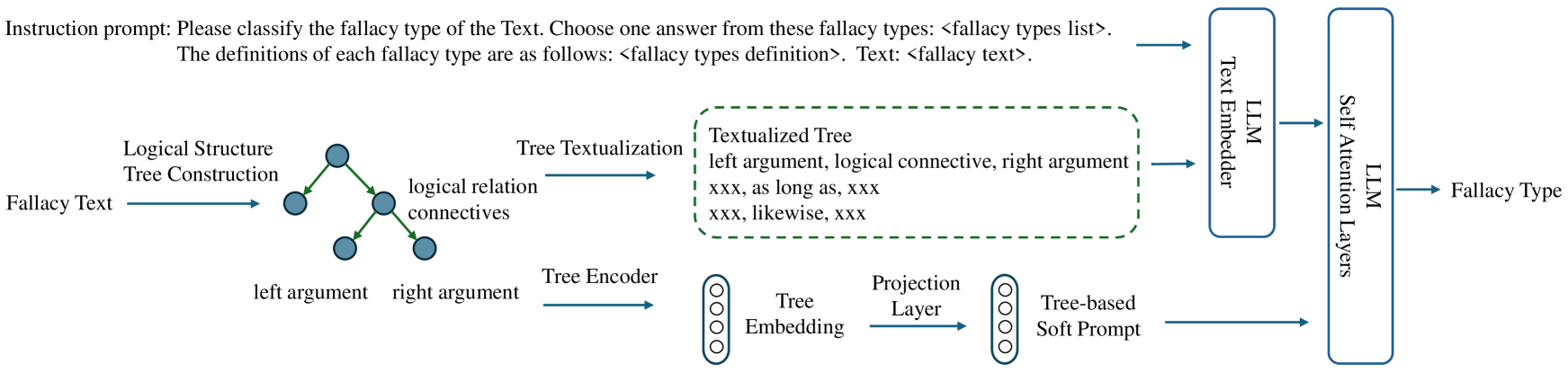
The image presents a system diagram illustrating a method for classifying fallacy types from text. It involves transforming fallacy text into a logical structure, encoding it, and then using a language model (LLM) to classify the fallacy type.
### Components/Axes
* **Instruction Prompt:** "Please classify the fallacy type of the Text. Choose one answer from these fallacy types: <fallacy types list>. The definitions of each fallacy type are as follows: <fallacy types definition>. Text: <fallacy text>."
* **Fallacy Text:** Input text containing a potential fallacy.
* **Logical Structure Tree Construction:** Represents the fallacy text as a tree structure. Nodes represent arguments, and edges represent logical relations.
* **Nodes:** Represented as blue circles.
* **Edges:** Represented as green lines, labeled "logical relation connectives".
* **Labels:** "left argument", "right argument"
* **Tree Textualization:** Converts the tree structure into a textual representation.
* **Textualized Tree:** Enclosed in a green dashed box.
* **Content:** "left argument, logical connective, right argument", "xxx, as long as, xxx", "xxx, likewise, xxx"
* **Tree Encoder:** Encodes the tree structure into an embedding.
* **Tree Embedding:** A stack of four circles.
* **Projection Layer:** Projects the tree embedding.
* **Tree-based Soft Prompt:** Output of the projection layer.
* **LLM Text Embedder:** Embeds the input fallacy text using a Language Model.
* **LLM Self Attention Layers:** Applies self-attention mechanisms using a Language Model.
* **Fallacy Type:** The final classification of the fallacy type.
### Detailed Analysis or Content Details
1. **Fallacy Text to Logical Structure:** The "Fallacy Text" is transformed into a "Logical Structure Tree Construction". This involves identifying the arguments and logical relations within the text and representing them as a tree.
2. **Tree Textualization:** The tree structure is converted into a textual format. The example text includes phrases like "as long as" and "likewise", suggesting that these phrases represent logical connectives.
3. **Tree Encoding:** The tree structure is encoded into a numerical representation (embedding) using a "Tree Encoder". This embedding captures the structural information of the tree.
4. **Projection Layer and Soft Prompt:** The "Projection Layer" transforms the "Tree Embedding" into a "Tree-based Soft Prompt". This prompt is likely used to guide the LLM in the classification task.
5. **LLM Processing:** The original "Fallacy Text" is embedded using an "LLM Text Embedder". The resulting embedding is then processed by "LLM Self Attention Layers".
6. **Fallacy Type Classification:** Finally, the output of the LLM is used to classify the "Fallacy Type".
### Key Observations
* The diagram illustrates a hybrid approach that combines structural information (tree representation) with semantic information (LLM embeddings) for fallacy classification.
* The "Tree Textualization" step suggests that the system can handle different types of logical connectives.
* The use of a "Tree-based Soft Prompt" indicates that the system is designed to leverage the structural information of the tree to improve the performance of the LLM.
### Interpretation
The diagram presents a novel approach to fallacy classification that leverages both the logical structure of the argument and the semantic understanding of a language model. By converting the fallacy text into a tree structure, the system can capture the relationships between different parts of the argument. This structural information is then combined with the semantic information extracted by the LLM to improve the accuracy of fallacy classification. The system appears to be designed to handle a variety of logical connectives and to leverage the structural information of the tree to guide the LLM in the classification task.