\n
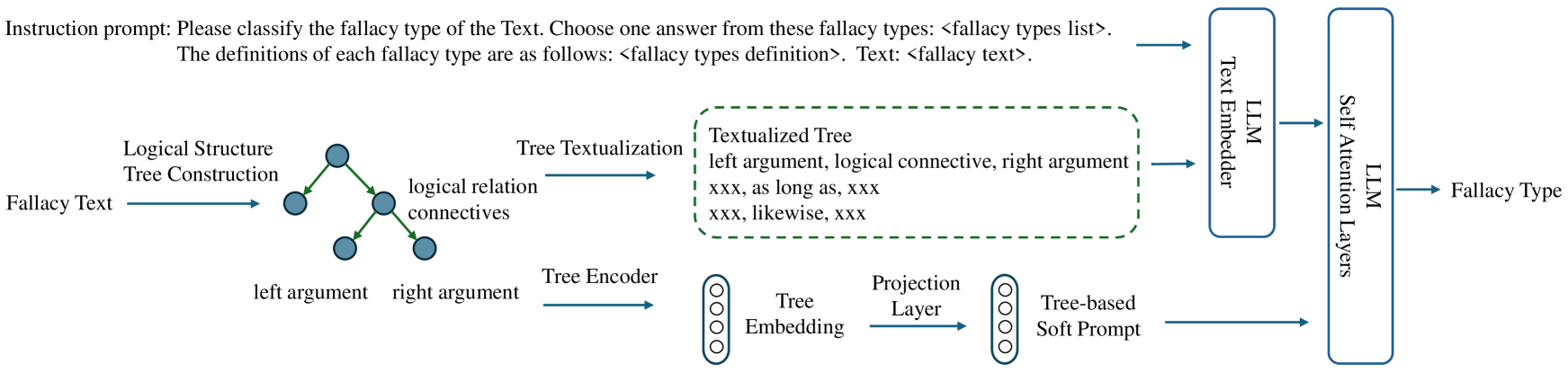
## Diagram: Fallacy Type Classification Pipeline
### Overview
This diagram illustrates a pipeline for classifying the type of fallacy present in a given text. The pipeline involves constructing a logical structure tree from the fallacy text, encoding the tree, and using a Large Language Model (LLM) with attention layers to predict the fallacy type.
### Components/Axes
The diagram consists of several interconnected components:
* **Input:** "Fallacy Text"
* **Logical Structure Tree Construction:** Converts the fallacy text into a tree structure.
* **Tree Textualization:** Transforms the tree into a textual representation. Examples provided: "xxx, as long as, xxx" and "xxx, likewise, xxx".
* **Tree Encoder:** Encodes the tree structure.
* **Tree Embedding:** Output of the Tree Encoder.
* **Projection Layer:** Transforms the Tree Embedding.
* **Tree-based Soft Prompt:** Output of the Projection Layer.
* **LLM Embedder:** Embeds the textualized tree.
* **LLM Attention Layers:** Processes the embedded tree.
* **Output:** "Fallacy Type"
* **Instruction Prompt:** "Please classify the fallacy type of the Text. Choose one answer from these fallacy types: <fallacy types list>. The definitions of each fallacy type are as follows: <fallacy types definition>. Text: <fallacy text>."
The diagram also shows the relationships between components using arrows indicating the flow of information.
### Detailed Analysis or Content Details
The pipeline begins with "Fallacy Text" as input. This text is then processed by "Logical Structure Tree Construction," which generates a tree representing the logical relationships within the text. The tree nodes are labeled as "left argument," "right argument," and "logical relation connectives."
The tree is then "Tree Textualization" which converts the tree into a textual format, with examples given as "xxx, as long as, xxx" and "xxx, likewise, xxx".
The textualized tree is then processed by a "Tree Encoder" which produces a "Tree Embedding". This embedding is then passed through a "Projection Layer" to create a "Tree-based Soft Prompt".
Simultaneously, the textualized tree is also fed into an "LLM Embedder". The output of the LLM Embedder, along with the "Tree-based Soft Prompt", are fed into "LLM Attention Layers".
Finally, the output of the LLM Attention Layers is used to predict the "Fallacy Type".
The top of the diagram shows an "Instruction Prompt" that is used to guide the LLM.
### Key Observations
The diagram highlights a multi-faceted approach to fallacy detection, combining structural analysis (tree construction) with semantic understanding (LLM embedding and attention). The use of both a "Tree-based Soft Prompt" and direct LLM embedding of the textualized tree suggests a hybrid approach to leveraging the tree structure within the LLM.
### Interpretation
This diagram represents a sophisticated system for automated fallacy detection. The pipeline aims to capture both the logical structure and the semantic content of the fallacy text. The use of a tree structure allows the system to explicitly represent the relationships between arguments, while the LLM provides the ability to understand the nuances of language and identify subtle fallacies. The combination of these two approaches could lead to more accurate and robust fallacy detection than either approach alone. The "Instruction Prompt" is crucial for guiding the LLM to provide the correct classification based on a predefined set of fallacy types and their definitions. The diagram suggests a focus on providing the LLM with structured information (the tree embedding and soft prompt) alongside the raw text to improve performance.