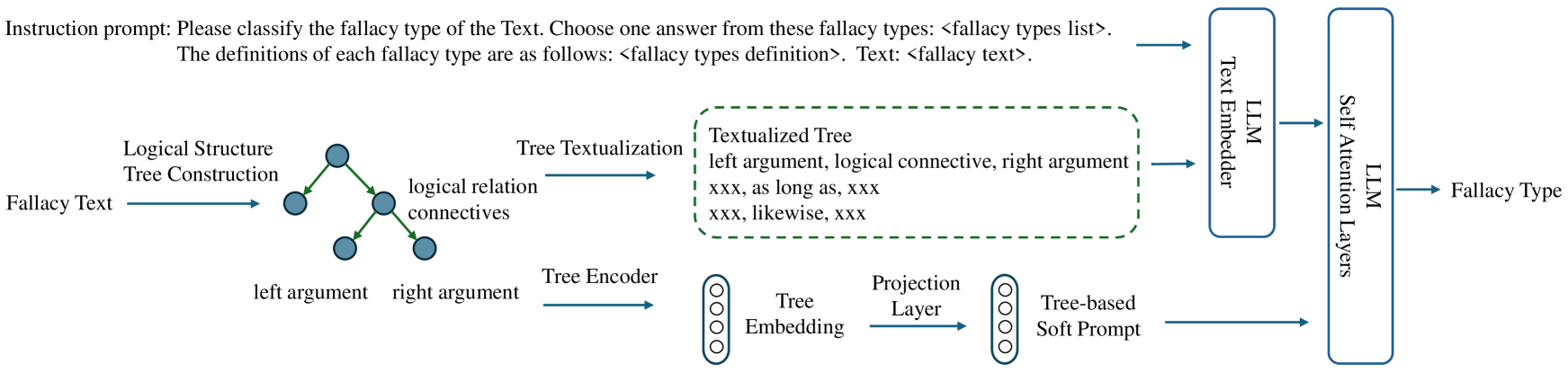
## Flowchart: Fallacy Type Classification System
### Overview
The diagram illustrates a technical pipeline for classifying fallacy types in text using a combination of logical structure analysis and machine learning components. The process begins with raw fallacy text and progresses through logical tree construction, textualization, encoding, and finally classification via large language model (LLM) components.
### Components/Axes
1. **Input**:
- "Fallacy Text" (top-left)
- "Fallacy Types List" (instruction prompt)
- "Fallacy Types Definition" (instruction prompt)
2. **Logical Structure Tree Construction**:
- Central node labeled "Logical Structure Tree Construction"
- Branches into:
- "left argument" (blue node)
- "right argument" (blue node)
- "logical relation connectives" (blue node)
3. **Tree Textualization**:
- Dashed green box containing:
- "Textualized Tree" format:
- "left argument, logical connective, right argument"
- Placeholders: "xxx, as long as, xxx" and "xxx, likewise, xxx"
4. **Tree Encoder**:
- Converts textualized tree into "Tree Embedding" (vertical blue cylinder)
5. **Projection Layer**:
- Converts embedding into "Tree-based Soft Prompt" (vertical blue cylinder)
6. **LLM Processing**:
- Two parallel components:
- "Text Embedder" (blue rectangle)
- "Self-Attention Layers" (blue rectangle)
- Both feed into final "Fallacy Type" output (rightmost)
### Detailed Analysis
- **Logical Structure**: The process begins by decomposing fallacy text into a logical structure tree with three components: left argument, right argument, and logical connective.
- **Textualization**: The tree is converted into a standardized textual format with explicit placeholders for arguments and connectives.
- **Encoding**: The textualized tree is encoded into embeddings, which are then projected into a soft prompt format.
- **LLM Integration**: Two LLM components process the prompt:
- Text Embedder: Converts text into vector representations
- Self-Attention Layers: Analyze relationships between components
- **Output**: Final classification as "Fallacy Type"
### Key Observations
1. The system emphasizes logical decomposition before machine learning processing
2. Placeholders ("xxx") indicate variable positions in the textualized tree format
3. Two distinct LLM components are used in parallel for processing
4. The flow moves from left-to-right and top-to-bottom spatially
5. No numerical data or quantitative metrics are shown
### Interpretation
This pipeline demonstrates a hybrid approach to fallacy detection that combines:
1. **Logical Analysis**: Explicit decomposition of arguments and connectives
2. **Structured Text Processing**: Standardized textual representation of logical structures
3. **Neural Processing**: Modern LLM components for contextual understanding
The use of both a Text Embedder and Self-Attention Layers suggests an attempt to balance semantic understanding with relational analysis. The textualized tree format with explicit placeholders indicates a need for consistent input formatting to the LLMs. The parallel processing of text embeddings and attention layers may help capture both surface-level patterns and deeper contextual relationships in the fallacy arguments.