## Bar Chart: Model Performance Comparison on MMLU Dataset
### Overview
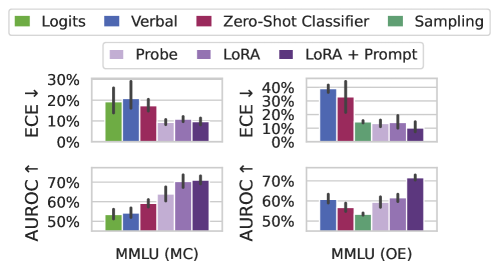
The image presents two sets of bar charts comparing the performance of different models on the MMLU (Massive Multitask Language Understanding) dataset. The charts are split into two scenarios: MMLU (MC) and MMLU (OE). Each scenario has two sub-charts, one showing the Expected Calibration Error (ECE) and the other showing the Area Under the Receiver Operating Characteristic curve (AUROC). The models being compared are Logits, Verbal, Zero-Shot Classifier, Sampling, Probe, LoRA, and LoRA + Prompt.
### Components/Axes
* **Legend:** Located at the top of the image.
* Green: Logits
* Blue: Verbal
* Maroon: Zero-Shot Classifier
* Light Green: Sampling
* Light Purple: Probe
* Purple: LoRA
* Dark Purple: LoRA + Prompt
* **Y-axis (ECE ↓):** Located on the left side of the top charts. Indicates Expected Calibration Error, with values ranging from 0% to 30% for MMLU (MC) and 0% to 40% for MMLU (OE). The down arrow indicates that lower ECE values are better.
* **Y-axis (AUROC ↑):** Located on the left side of the bottom charts. Indicates Area Under the Receiver Operating Characteristic curve, with values ranging from 50% to 70%. The up arrow indicates that higher AUROC values are better.
* **X-axis:** Represents the different models being compared within each MMLU scenario.
* **X-axis Labels:** MMLU (MC) and MMLU (OE) indicate the specific MMLU scenario being evaluated.
### Detailed Analysis
**MMLU (MC) - ECE ↓**
* **Logits (Green):** ECE is approximately 19%, with an uncertainty of +/- 5%.
* **Verbal (Blue):** ECE is approximately 20%, with an uncertainty of +/- 8%.
* **Zero-Shot Classifier (Maroon):** ECE is approximately 17%, with an uncertainty of +/- 4%.
* **Sampling (Light Green):** ECE is approximately 12%, with an uncertainty of +/- 2%.
* **Probe (Light Purple):** ECE is approximately 10%, with an uncertainty of +/- 2%.
* **LoRA (Purple):** ECE is approximately 11%, with an uncertainty of +/- 2%.
* **LoRA + Prompt (Dark Purple):** ECE is approximately 9%, with an uncertainty of +/- 2%.
**MMLU (MC) - AUROC ↑**
* **Logits (Green):** AUROC is approximately 53%, with an uncertainty of +/- 3%.
* **Verbal (Blue):** AUROC is approximately 55%, with an uncertainty of +/- 3%.
* **Zero-Shot Classifier (Maroon):** AUROC is approximately 59%, with an uncertainty of +/- 3%.
* **Sampling (Light Green):** AUROC is approximately 63%, with an uncertainty of +/- 5%.
* **Probe (Light Purple):** AUROC is approximately 68%, with an uncertainty of +/- 4%.
* **LoRA (Purple):** AUROC is approximately 70%, with an uncertainty of +/- 3%.
* **LoRA + Prompt (Dark Purple):** AUROC is approximately 71%, with an uncertainty of +/- 3%.
**MMLU (OE) - ECE ↓**
* **Logits (Green):** ECE is approximately 15%, with an uncertainty of +/- 2%.
* **Verbal (Blue):** ECE is approximately 38%, with an uncertainty of +/- 3%.
* **Zero-Shot Classifier (Maroon):** ECE is approximately 32%, with an uncertainty of +/- 9%.
* **Sampling (Light Green):** ECE is approximately 15%, with an uncertainty of +/- 2%.
* **Probe (Light Purple):** ECE is approximately 15%, with an uncertainty of +/- 2%.
* **LoRA (Purple):** ECE is approximately 18%, with an uncertainty of +/- 3%.
* **LoRA + Prompt (Dark Purple):** ECE is approximately 10%, with an uncertainty of +/- 2%.
**MMLU (OE) - AUROC ↑**
* **Logits (Green):** AUROC is approximately 53%, with an uncertainty of +/- 2%.
* **Verbal (Blue):** AUROC is approximately 60%, with an uncertainty of +/- 3%.
* **Zero-Shot Classifier (Maroon):** AUROC is approximately 57%, with an uncertainty of +/- 4%.
* **Sampling (Light Green):** AUROC is approximately 52%, with an uncertainty of +/- 2%.
* **Probe (Light Purple):** AUROC is approximately 60%, with an uncertainty of +/- 3%.
* **LoRA (Purple):** AUROC is approximately 63%, with an uncertainty of +/- 3%.
* **LoRA + Prompt (Dark Purple):** AUROC is approximately 71%, with an uncertainty of +/- 3%.
### Key Observations
* **ECE Trends:** In MMLU (MC), ECE generally decreases from Logits to LoRA + Prompt. In MMLU (OE), Verbal and Zero-Shot Classifier have significantly higher ECE compared to other models.
* **AUROC Trends:** In both MMLU (MC) and MMLU (OE), AUROC generally increases from Logits to LoRA + Prompt.
* **Model Performance:** LoRA + Prompt consistently shows the best AUROC and lowest ECE in both MMLU scenarios.
* **Verbal and Zero-Shot Classifier Anomaly:** In MMLU (OE), Verbal and Zero-Shot Classifier exhibit significantly higher ECE values compared to their performance in MMLU (MC) and compared to other models in MMLU (OE).
### Interpretation
The data suggests that fine-tuning language models with LoRA (Low-Rank Adaptation) and prompting techniques (LoRA + Prompt) significantly improves performance on the MMLU dataset, as indicated by higher AUROC and lower ECE values. The MMLU (MC) scenario shows a more consistent improvement across models, while MMLU (OE) reveals that certain models (Verbal and Zero-Shot Classifier) struggle with calibration, leading to higher ECE. This could indicate that these models are overconfident in their predictions in the MMLU (OE) setting. The consistent improvement of LoRA + Prompt across both scenarios highlights the effectiveness of this approach for enhancing language model performance and calibration.