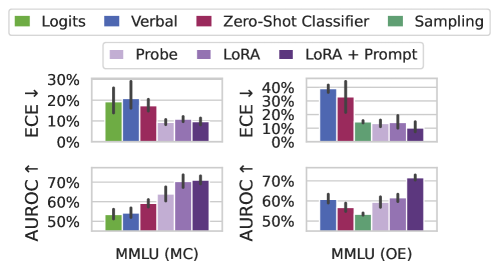
## Bar Chart: Performance Comparison of Methods Across Tasks and Metrics
### Overview
The image is a grouped bar chart comparing the performance of various methods (Logits, Verbal, Zero-Shot Classifier, Sampling, Probe, LoRA, LoRA + Prompt) across two tasks (MMLU MC and MMLU OE) and two metrics (ECE ↓ and AUROC ↑). The chart uses color-coded bars to represent different methods and evaluation types, with error bars indicating variability.
### Components/Axes
- **X-Axis**:
- Categories:
1. MMLU (MC) - ECE ↓
2. MMLU (OE) - ECE ↓
3. MMLU (MC) - AUROC ↑
4. MMLU (OE) - AUROC ↑
- **Y-Axis**:
- ECE ↓: 0% to 30% (top chart)
- AUROC ↑: 50% to 70% (bottom chart)
- **Legends**:
- **Top Legend**:
- Green: Logits
- Blue: Verbal
- Red: Zero-Shot Classifier
- Green: Sampling
- **Bottom Legend**:
- Purple: Probe
- Dark Purple: LoRA
- Dark Purple: LoRA + Prompt
### Detailed Analysis
#### MMLU (MC) - ECE ↓
- **Logits (Green)**: ~20% (highest)
- **Verbal (Blue)**: ~25% (highest)
- **Zero-Shot Classifier (Red)**: ~15%
- **Sampling (Green)**: ~10%
- **Probe (Purple)**: ~12%
- **LoRA (Dark Purple)**: ~10%
- **LoRA + Prompt (Dark Purple)**: ~8% (lowest)
#### MMLU (OE) - ECE ↓
- **Verbal (Blue)**: ~35% (highest)
- **Zero-Shot Classifier (Red)**: ~30%
- **Sampling (Green)**: ~15%
- **Probe (Purple)**: ~10%
- **LoRA (Dark Purple)**: ~12%
- **LoRA + Prompt (Dark Purple)**: ~5% (lowest)
#### MMLU (MC) - AUROC ↑
- **Logits (Green)**: ~50% (lowest)
- **Verbal (Blue)**: ~55%
- **Zero-Shot Classifier (Red)**: ~60%
- **Sampling (Green)**: ~55%
- **Probe (Purple)**: ~65%
- **LoRA (Dark Purple)**: ~68%
- **LoRA + Prompt (Dark Purple)**: ~70% (highest)
#### MMLU (OE) - AUROC ↑
- **Logits (Green)**: ~55%
- **Verbal (Blue)**: ~60%
- **Zero-Shot Classifier (Red)**: ~55%
- **Sampling (Green)**: ~50%
- **Probe (Purple)**: ~60%
- **LoRA (Dark Purple)**: ~65%
- **LoRA + Prompt (Dark Purple)**: ~70% (highest)
### Key Observations
1. **ECE ↓ Trends**:
- Verbal and Zero-Shot Classifier consistently show the highest ECE ↓ (lower confidence) across both tasks.
- LoRA + Prompt achieves the lowest ECE ↓ (highest confidence) in MMLU (OE).
2. **AUROC ↑ Trends**:
- LoRA + Prompt dominates in AUROC ↑, reaching ~70% in both tasks.
- Logits and Sampling underperform, with AUROC ↑ values near 50-55% in MMLU (MC).
3. **Task-Specific Performance**:
- MMLU (OE) generally shows higher AUROC ↑ and lower ECE ↓ compared to MMLU (MC), suggesting better generalization in open-ended tasks.
### Interpretation
The data highlights that **LoRA + Prompt** outperforms other methods in both metrics, particularly in the MMLU (OE) task, where it achieves the highest AUROC ↑ (~70%) and lowest ECE ↓ (~5%). This suggests that LoRA + Prompt enhances model confidence and accuracy in open-ended scenarios. Conversely, **Verbal** and **Zero-Shot Classifier** methods exhibit the highest ECE ↓, indicating lower confidence, especially in MMLU (OE). The **Sampling** and **Probe** methods fall in the middle, with moderate performance. The chart underscores the importance of method selection based on task complexity, with LoRA + Prompt being the most robust choice for generalization.