TECHNICAL ASSET FINGERPRINT
621921426a097fe8466f1154
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: gemma-3-27b-it-free VERSION 1
RUNTIME: google-free/gemma-3-27b-it
INTEL_VERIFIED
\n
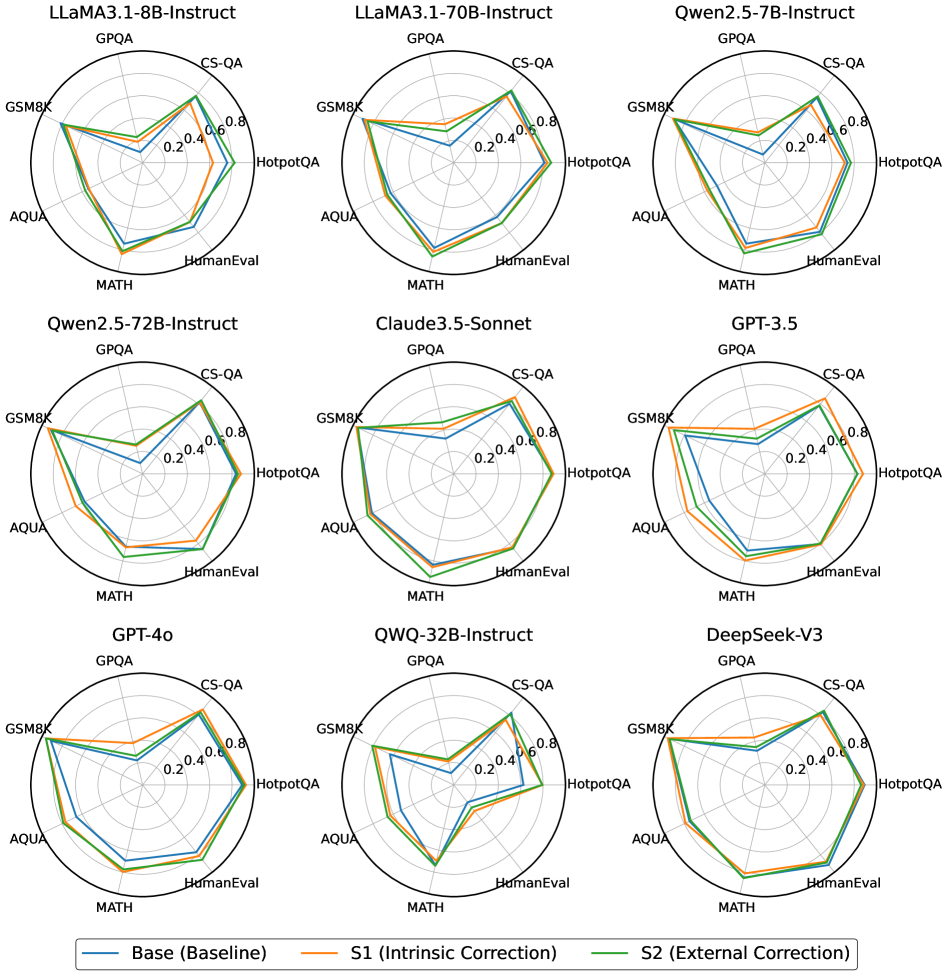
## Radar Charts: Model Performance Comparison
### Overview
The image presents a 3x3 grid of radar charts, each representing the performance of a different Large Language Model (LLM) across six different question answering/reasoning benchmarks. Each chart displays three lines, representing different correction strategies applied to the model. The benchmarks are arranged radially around the chart's center.
### Components/Axes
* **Radial Axes:** Representing the following benchmarks:
* MATH
* AQUA
* GSM8K
* CS-QA
* HotpotQA
* GPQA
* HumanEval
* **Radial Scale:** Ranges from 0.0 to 0.8, with increments of 0.2.
* **Legend (Bottom-Center):**
* Base (Baseline) - Represented by a light orange line.
* S1 (Intrinsic Correction) - Represented by a green line.
* S2 (External Correction) - Represented by a blue line.
* **Chart Titles (Top-Center of each chart):** Indicate the LLM being evaluated. The models are:
* LLaMA3.1-8B-Instruct
* LLaMA3.1-70B-Instruct
* Qwen2.5-7B-Instruct
* Qwen2.5-72B-Instruct
* Claude3.5-Sonnet
* GPT-3.5
* GPT-4o
* QWQ-32B-Instruct
* DeepSeek-V3
### Detailed Analysis or Content Details
Each chart will be analyzed individually, noting trends and approximate values.
**1. LLaMA3.1-8B-Instruct:**
* **Base (Orange):** Starts low at MATH (~0.1), rises to a peak at GSM8K (~0.6), dips at CS-QA (~0.3), rises again at HotpotQA (~0.5), dips at AQUA (~0.2), and ends at HumanEval (~0.3).
* **S1 (Green):** Similar to Base, but generally higher. Starts at MATH (~0.2), peaks at GSM8K (~0.7), dips at CS-QA (~0.4), rises at HotpotQA (~0.6), dips at AQUA (~0.3), and ends at HumanEval (~0.4).
* **S2 (Blue):** Starts at MATH (~0.2), peaks at GSM8K (~0.7), dips at CS-QA (~0.4), rises at HotpotQA (~0.6), dips at AQUA (~0.3), and ends at HumanEval (~0.4).
**2. LLaMA3.1-70B-Instruct:**
* **Base (Orange):** Starts at MATH (~0.2), rises to GSM8K (~0.7), dips at CS-QA (~0.4), rises at HotpotQA (~0.6), dips at AQUA (~0.3), and ends at HumanEval (~0.4).
* **S1 (Green):** Starts at MATH (~0.3), peaks at GSM8K (~0.8), dips at CS-QA (~0.5), rises at HotpotQA (~0.7), dips at AQUA (~0.4), and ends at HumanEval (~0.5).
* **S2 (Blue):** Starts at MATH (~0.3), peaks at GSM8K (~0.8), dips at CS-QA (~0.5), rises at HotpotQA (~0.7), dips at AQUA (~0.4), and ends at HumanEval (~0.5).
**3. Qwen2.5-7B-Instruct:**
* **Base (Orange):** Starts at MATH (~0.1), rises to GSM8K (~0.5), dips at CS-QA (~0.3), rises at HotpotQA (~0.4), dips at AQUA (~0.2), and ends at HumanEval (~0.3).
* **S1 (Green):** Starts at MATH (~0.2), peaks at GSM8K (~0.6), dips at CS-QA (~0.4), rises at HotpotQA (~0.5), dips at AQUA (~0.3), and ends at HumanEval (~0.4).
* **S2 (Blue):** Starts at MATH (~0.2), peaks at GSM8K (~0.6), dips at CS-QA (~0.4), rises at HotpotQA (~0.5), dips at AQUA (~0.3), and ends at HumanEval (~0.4).
**4. Qwen2.5-72B-Instruct:**
* **Base (Orange):** Starts at MATH (~0.2), rises to GSM8K (~0.7), dips at CS-QA (~0.4), rises at HotpotQA (~0.6), dips at AQUA (~0.3), and ends at HumanEval (~0.4).
* **S1 (Green):** Starts at MATH (~0.3), peaks at GSM8K (~0.8), dips at CS-QA (~0.5), rises at HotpotQA (~0.7), dips at AQUA (~0.4), and ends at HumanEval (~0.5).
* **S2 (Blue):** Starts at MATH (~0.3), peaks at GSM8K (~0.8), dips at CS-QA (~0.5), rises at HotpotQA (~0.7), dips at AQUA (~0.4), and ends at HumanEval (~0.5).
**5. Claude3.5-Sonnet:**
* **Base (Orange):** Starts at MATH (~0.2), rises to GSM8K (~0.7), dips at CS-QA (~0.4), rises at HotpotQA (~0.6), dips at AQUA (~0.3), and ends at HumanEval (~0.4).
* **S1 (Green):** Starts at MATH (~0.3), peaks at GSM8K (~0.8), dips at CS-QA (~0.5), rises at HotpotQA (~0.7), dips at AQUA (~0.4), and ends at HumanEval (~0.5).
* **S2 (Blue):** Starts at MATH (~0.3), peaks at GSM8K (~0.8), dips at CS-QA (~0.5), rises at HotpotQA (~0.7), dips at AQUA (~0.4), and ends at HumanEval (~0.5).
**6. GPT-3.5:**
* **Base (Orange):** Starts at MATH (~0.1), rises to GSM8K (~0.5), dips at CS-QA (~0.3), rises at HotpotQA (~0.4), dips at AQUA (~0.2), and ends at HumanEval (~0.3).
* **S1 (Green):** Starts at MATH (~0.2), peaks at GSM8K (~0.6), dips at CS-QA (~0.4), rises at HotpotQA (~0.5), dips at AQUA (~0.3), and ends at HumanEval (~0.4).
* **S2 (Blue):** Starts at MATH (~0.2), peaks at GSM8K (~0.6), dips at CS-QA (~0.4), rises at HotpotQA (~0.5), dips at AQUA (~0.3), and ends at HumanEval (~0.4).
**7. GPT-4o:**
* **Base (Orange):** Starts at MATH (~0.3), rises to GSM8K (~0.8), dips at CS-QA (~0.6), rises at HotpotQA (~0.8), dips at AQUA (~0.5), and ends at HumanEval (~0.6).
* **S1 (Green):** Starts at MATH (~0.4), peaks at GSM8K (~0.9), dips at CS-QA (~0.7), rises at HotpotQA (~0.9), dips at AQUA (~0.6), and ends at HumanEval (~0.7).
* **S2 (Blue):** Starts at MATH (~0.4), peaks at GSM8K (~0.9), dips at CS-QA (~0.7), rises at HotpotQA (~0.9), dips at AQUA (~0.6), and ends at HumanEval (~0.7).
**8. QWQ-32B-Instruct:**
* **Base (Orange):** Starts at MATH (~0.2), rises to GSM8K (~0.7), dips at CS-QA (~0.4), rises at HotpotQA (~0.6), dips at AQUA (~0.3), and ends at HumanEval (~0.4).
* **S1 (Green):** Starts at MATH (~0.3), peaks at GSM8K (~0.8), dips at CS-QA (~0.5), rises at HotpotQA (~0.7), dips at AQUA (~0.4), and ends at HumanEval (~0.5).
* **S2 (Blue):** Starts at MATH (~0.3), peaks at GSM8K (~0.8), dips at CS-QA (~0.5), rises at HotpotQA (~0.7), dips at AQUA (~0.4), and ends at HumanEval (~0.5).
**9. DeepSeek-V3:**
* **Base (Orange):** Starts at MATH (~0.2), rises to GSM8K (~0.7), dips at CS-QA (~0.4), rises at HotpotQA (~0.6), dips at AQUA (~0.3), and ends at HumanEval (~0.4).
* **S1 (Green):** Starts at MATH (~0.3), peaks at GSM8K (~0.8), dips at CS-QA (~0.5), rises at HotpotQA (~0.7), dips at AQUA (~0.4), and ends at HumanEval (~0.5).
* **S2 (Blue):** Starts at MATH (~0.3), peaks at GSM8K (~0.8), dips at CS-QA (~0.5), rises at HotpotQA (~0.7), dips at AQUA (~0.4), and ends at HumanEval (~0.5).
### Key Observations
* Generally, S1 and S2 consistently outperform the Base model across all benchmarks and for all LLMs.
* GSM8K consistently shows the highest performance for all models, regardless of correction strategy.
* AQUA consistently shows the lowest performance for all models, regardless of correction strategy.
* GPT-4o consistently demonstrates the highest overall performance.
* The larger models (70B parameters) generally outperform their smaller counterparts (8B parameters) within the LLaMA and Qwen families.
### Interpretation
The radar charts demonstrate the effectiveness of intrinsic (S1) and external (S2) correction strategies in improving the performance of various LLMs across a range of reasoning and question-answering benchmarks. The consistent outperformance of S1 and S2 suggests that these correction methods are broadly applicable and beneficial. The varying performance across benchmarks highlights the strengths and weaknesses of each model. The dominance of GSM8K suggests that these models are relatively strong at mathematical reasoning, while the lower scores on AQUA indicate a weakness in complex reasoning or knowledge-intensive tasks. The superior performance of GPT-4o confirms its position as a leading LLM. The charts provide a valuable comparative analysis of LLM capabilities and the impact of different correction techniques, offering insights for model development and selection. The consistent shape of the radar charts across models suggests a common underlying pattern of strengths and weaknesses, with correction strategies providing a uniform boost.
DECODING INTELLIGENCE...