TECHNICAL ASSET FINGERPRINT
621921426a097fe8466f1154
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
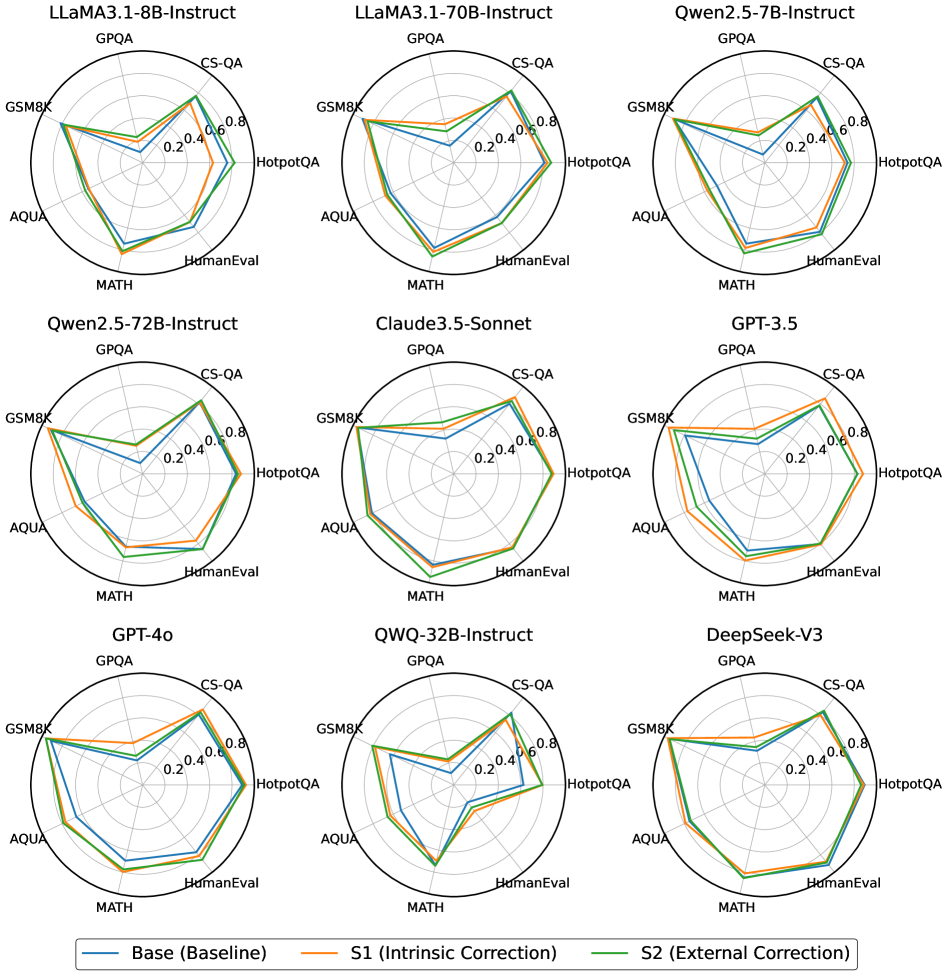
## Radar Chart Comparison: AI Model Performance Across Benchmarks with Correction Methods
### Overview
The image displays a 3x3 grid of nine radar charts (spider charts). Each chart compares the performance of a specific Large Language Model (LLM) across seven different evaluation benchmarks. For each model, three performance lines are plotted, representing a baseline ("Base") and two correction methods ("S1" and "S2"). The charts collectively visualize how different correction techniques impact model performance across a standardized set of tasks.
### Components/Axes
* **Chart Type:** Radar Charts (Spider Charts).
* **Grid Layout:** 3 rows x 3 columns.
* **Model Titles (Top of each chart, reading left-to-right, top-to-bottom):**
1. LLaMA3.1-8B-Instruct
2. LLaMA3.1-70B-Instruct
3. Qwen2.5-7B-Instruct
4. Qwen2.5-72B-Instruct
5. Claude3.5-Sonnet
6. GPT-3.5
7. GPT-4o
8. QWQ-32B-Instruct
9. DeepSeek-V3
* **Axes (Benchmarks):** Each chart has seven axes radiating from the center, labeled clockwise from the top:
1. GPQA (Graduate-level Google-Proof Q&A)
2. CS-QA (Computer Science Q&A)
3. HotpotQA (Multi-hop reasoning Q&A)
4. HumanEval (Code generation)
5. MATH (Mathematical problem-solving)
6. AQUA (Algebraic word problems)
7. GSM8K (Grade School Math)
* **Scale:** Each axis has a concentric grid with values marked at 0.2, 0.4, 0.6, and 0.8. The center represents 0.0, and the outermost ring represents 1.0 (implied).
* **Legend (Bottom center of the entire image):**
* **Blue Line:** Base (Baseline)
* **Orange Line:** S1 (Intrinsic Correction)
* **Green Line:** S2 (External Correction)
### Detailed Analysis
Below is an approximate data extraction for each model. Values are estimated based on the line's intersection with each axis. The trend for each correction method (S1, S2) is described relative to the Base (Blue) line.
**1. LLaMA3.1-8B-Instruct**
* **Trend:** S1 (Orange) shows minor improvements over Base. S2 (Green) shows significant improvement, especially on GSM8K and MATH.
* **Approximate Values (Base / S1 / S2):**
* GPQA: ~0.35 / ~0.38 / ~0.40
* CS-QA: ~0.55 / ~0.58 / ~0.60
* HotpotQA: ~0.50 / ~0.52 / ~0.55
* HumanEval: ~0.45 / ~0.48 / ~0.50
* MATH: ~0.30 / ~0.35 / ~0.55
* AQUA: ~0.40 / ~0.42 / ~0.45
* GSM8K: ~0.50 / ~0.55 / ~0.75
**2. LLaMA3.1-70B-Instruct**
* **Trend:** S1 and S2 provide modest, consistent improvements across most benchmarks over the Base.
* **Approximate Values (Base / S1 / S2):**
* GPQA: ~0.50 / ~0.52 / ~0.55
* CS-QA: ~0.65 / ~0.68 / ~0.70
* HotpotQA: ~0.60 / ~0.62 / ~0.65
* HumanEval: ~0.55 / ~0.58 / ~0.60
* MATH: ~0.45 / ~0.50 / ~0.60
* AQUA: ~0.50 / ~0.52 / ~0.55
* GSM8K: ~0.65 / ~0.70 / ~0.80
**3. Qwen2.5-7B-Instruct**
* **Trend:** S1 shows slight gains. S2 shows more pronounced gains, particularly on GSM8K and MATH.
* **Approximate Values (Base / S1 / S2):**
* GPQA: ~0.40 / ~0.42 / ~0.45
* CS-QA: ~0.60 / ~0.62 / ~0.65
* HotpotQA: ~0.55 / ~0.57 / ~0.60
* HumanEval: ~0.50 / ~0.52 / ~0.55
* MATH: ~0.35 / ~0.40 / ~0.60
* AQUA: ~0.45 / ~0.47 / ~0.50
* GSM8K: ~0.55 / ~0.60 / ~0.80
**4. Qwen2.5-72B-Instruct**
* **Trend:** Both S1 and S2 show clear improvements over Base across all axes, with S2 generally outperforming S1.
* **Approximate Values (Base / S1 / S2):**
* GPQA: ~0.55 / ~0.58 / ~0.60
* CS-QA: ~0.70 / ~0.72 / ~0.75
* HotpotQA: ~0.65 / ~0.68 / ~0.70
* HumanEval: ~0.60 / ~0.62 / ~0.65
* MATH: ~0.50 / ~0.55 / ~0.65
* AQUA: ~0.55 / ~0.58 / ~0.60
* GSM8K: ~0.70 / ~0.75 / ~0.85
**5. Claude3.5-Sonnet**
* **Trend:** High baseline performance. S1 and S2 provide incremental improvements, with S2 showing the largest gains on GSM8K and MATH.
* **Approximate Values (Base / S1 / S2):**
* GPQA: ~0.65 / ~0.68 / ~0.70
* CS-QA: ~0.75 / ~0.78 / ~0.80
* HotpotQA: ~0.70 / ~0.72 / ~0.75
* HumanEval: ~0.65 / ~0.68 / ~0.70
* MATH: ~0.55 / ~0.60 / ~0.70
* AQUA: ~0.60 / ~0.62 / ~0.65
* GSM8K: ~0.75 / ~0.80 / ~0.90
**6. GPT-3.5**
* **Trend:** S1 and S2 corrections yield noticeable improvements across all benchmarks, with S2 consistently higher.
* **Approximate Values (Base / S1 / S2):**
* GPQA: ~0.45 / ~0.48 / ~0.50
* CS-QA: ~0.60 / ~0.63 / ~0.65
* HotpotQA: ~0.55 / ~0.58 / ~0.60
* HumanEval: ~0.50 / ~0.53 / ~0.55
* MATH: ~0.40 / ~0.45 / ~0.55
* AQUA: ~0.45 / ~0.48 / ~0.50
* GSM8K: ~0.60 / ~0.65 / ~0.80
**7. GPT-4o**
* **Trend:** Strong baseline. S1 provides small gains. S2 provides more substantial gains, especially on GSM8K and MATH, pushing performance near the outer edge of the chart.
* **Approximate Values (Base / S1 / S2):**
* GPQA: ~0.60 / ~0.62 / ~0.65
* CS-QA: ~0.70 / ~0.72 / ~0.75
* HotpotQA: ~0.65 / ~0.68 / ~0.70
* HumanEval: ~0.60 / ~0.62 / ~0.65
* MATH: ~0.50 / ~0.55 / ~0.70
* AQUA: ~0.55 / ~0.58 / ~0.60
* GSM8K: ~0.70 / ~0.75 / ~0.90
**8. QWQ-32B-Instruct**
* **Trend:** S1 shows minimal change from Base. S2 shows a dramatic expansion, particularly on GSM8K, MATH, and AQUA, creating a much larger area.
* **Approximate Values (Base / S1 / S2):**
* GPQA: ~0.40 / ~0.40 / ~0.45
* CS-QA: ~0.55 / ~0.55 / ~0.60
* HotpotQA: ~0.50 / ~0.50 / ~0.55
* HumanEval: ~0.45 / ~0.45 / ~0.50
* MATH: ~0.30 / ~0.35 / ~0.60
* AQUA: ~0.35 / ~0.38 / ~0.55
* GSM8K: ~0.50 / ~0.55 / ~0.85
**9. DeepSeek-V3**
* **Trend:** S1 provides slight improvements. S2 provides more significant improvements, with the largest gains on GSM8K and MATH.
* **Approximate Values (Base / S1 / S2):**
* GPQA: ~0.50 / ~0.52 / ~0.55
* CS-QA: ~0.65 / ~0.68 / ~0.70
* HotpotQA: ~0.60 / ~0.62 / ~0.65
* HumanEval: ~0.55 / ~0.58 / ~0.60
* MATH: ~0.45 / ~0.50 / ~0.65
* AQUA: ~0.50 / ~0.52 / ~0.55
* GSM8K: ~0.65 / ~0.70 / ~0.85
### Key Observations
1. **Universal Improvement from S2:** In every single chart, the Green line (S2 - External Correction) encloses the largest area, indicating it provides the most significant performance boost across the board compared to the Base and S1 methods.
2. **GSM8K and MATH are Most Responsive:** The benchmarks GSM8K (Grade School Math) and MATH show the most dramatic improvements when applying the S2 correction method across nearly all models. The green line spikes sharply outward on these axes.
3. **Model Size Correlation:** Larger models (e.g., LLaMA3.1-70B, Qwen2.5-72B, Claude3.5-Sonnet, GPT-4o) generally have higher baseline (blue) performance and maintain a more balanced, larger shape across all benchmarks.
4. **S1 vs. S2 Efficacy:** The S1 (Intrinsic Correction) method typically provides modest, incremental gains over the baseline. The S2 method is consistently more powerful, often transforming the performance profile, especially on reasoning-heavy tasks (MATH, GSM8K).
5. **Specialized Performance:** Some models show more pronounced "spikes" on certain axes even after correction (e.g., QWQ-32B's massive GSM8K spike with S2), suggesting the corrections may be particularly effective for specific types of reasoning tasks.
### Interpretation
This visualization demonstrates the efficacy of two different correction techniques ("Intrinsic" S1 and "External" S2) on a suite of diverse AI models. The data strongly suggests that **External Correction (S2) is a universally more effective method** for boosting performance across a wide range of cognitive tasks, from mathematical reasoning (MATH, GSM8K) to code generation (HumanEval) and complex Q&A (GPQA, HotpotQA).
The consistent, dramatic improvement on GSM8K and MATH indicates that these mathematical reasoning benchmarks may be particularly susceptible to the type of enhancement provided by the S2 method. This could imply that S2 involves techniques like improved tool use, external knowledge retrieval, or specialized reasoning chains that are highly beneficial for quantitative tasks.
Furthermore, the charts reveal that while larger, more capable models start with a higher baseline, they still benefit significantly from these corrections, especially S2. This suggests that even state-of-the-art models have room for improvement through post-hoc or integrated correction mechanisms. The relative shapes of the polygons also hint at model "specializations"—some models may have inherent strengths in certain domains (like code or math) that are amplified or balanced by the correction methods.
In essence, the image provides a compelling argument for the development and application of advanced correction techniques (particularly the "External" S2 approach) as a key strategy for enhancing the reliability and capability of AI systems across a broad spectrum of challenging tasks.
DECODING INTELLIGENCE...