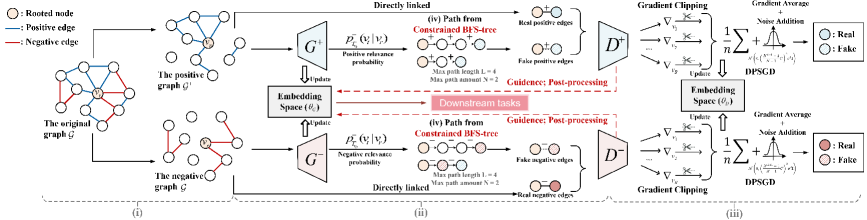
## Diagram: Graph Embedding and Differential Privacy
### Overview
The image is a diagram illustrating a process for graph embedding with differential privacy. It shows how an original graph is transformed into positive and negative graphs, embedded into a space, and then processed with gradient clipping and noise addition to ensure privacy.
### Components/Axes
The diagram is divided into three main sections, labeled (i), (ii), and (iii).
**Legend (Top-Left)**
* Rooted node: Represented by a white circle.
* Positive edge: Represented by a blue line.
* Negative edge: Represented by a red line.
**Section (i): Graph Creation**
* The original graph G is shown with a mix of positive (blue) and negative (red) edges connecting nodes. One node is marked as the "Rooted node".
* The original graph G is transformed into:
* The positive graph G', which contains positive edges (blue).
* The negative graph G', which contains negative edges (red).
**Section (ii): Embedding Space and Path Generation**
* Two blocks labeled G+ and G- represent transformations of the positive and negative graphs, respectively.
* G+ is associated with "Positive relevance probability" denoted as p+_{E}(v_i | v_r).
* G- is associated with "Negative relevance probability" denoted as p-_{E}(v_i | v_r).
* An "Embedding Space (θ_E)" block sits between G+ and G-, with arrows indicating "Update" from G+ and G- and to G+ and G-.
* "Downstream tasks" is written in a red box, with dashed red arrows pointing to and from the "Embedding Space (θ_E)".
* Path Generation:
* "(iv) Path from Constrained BFS-tree" is shown for both positive and negative graphs.
* The path consists of connected nodes.
* "Max path length L = 4" and "Max path amount N = 2" are specified.
* "Guidance: Post-processing" is indicated.
* Real and fake positive/negative edges are shown as pairs of nodes connected by either a blue or red line.
**Section (iii): Differential Privacy**
* Two blocks labeled D+ and D- represent differential privacy processing for positive and negative graphs, respectively.
* "Gradient Clipping" is applied to both D+ and D-.
* The gradients are represented as ∇v_i.
* A summation formula is shown: 1/n * Σ ∇v_i.
* "Gradient Average + Noise Addition" is applied. The noise is represented by a Gaussian distribution N(0, (λ(e^(λ/2)-1)/n^2) * σ^2).
* "DPSGD" (Differentially Private Stochastic Gradient Descent) is indicated.
* The output consists of "Real" and "Fake" nodes, colored blue and white for D+, and red and white with diagonal lines for D-.
### Detailed Analysis
* **Graph Creation (i):** The original graph is split into positive and negative graphs, likely based on edge types or relationships.
* **Embedding Space (ii):** The positive and negative graphs are embedded into a shared space, which is updated based on the relevance probabilities.
* **Path Generation (ii):** Paths are generated from the embedded graphs using a constrained Breadth-First Search (BFS) tree. The maximum path length and amount are limited.
* **Differential Privacy (iii):** Gradient clipping and noise addition are applied to the gradients to ensure differential privacy during the learning process.
### Key Observations
* The diagram illustrates a process for learning graph embeddings while preserving privacy.
* The use of both positive and negative graphs suggests a contrastive learning approach.
* The differential privacy mechanism involves gradient clipping and noise addition, which are standard techniques for protecting sensitive information.
### Interpretation
The diagram presents a method for creating graph embeddings that are both informative and privacy-preserving. The process involves transforming the original graph into positive and negative representations, embedding these representations into a shared space, and then applying differential privacy techniques to protect sensitive information during the learning process. The "Downstream tasks" element suggests that these embeddings are intended to be used for further analysis or prediction. The use of constrained BFS trees for path generation likely aims to capture relevant relationships within the graph while limiting computational complexity. The overall approach balances the need for accurate graph representations with the requirement to protect the privacy of the underlying data.