\n
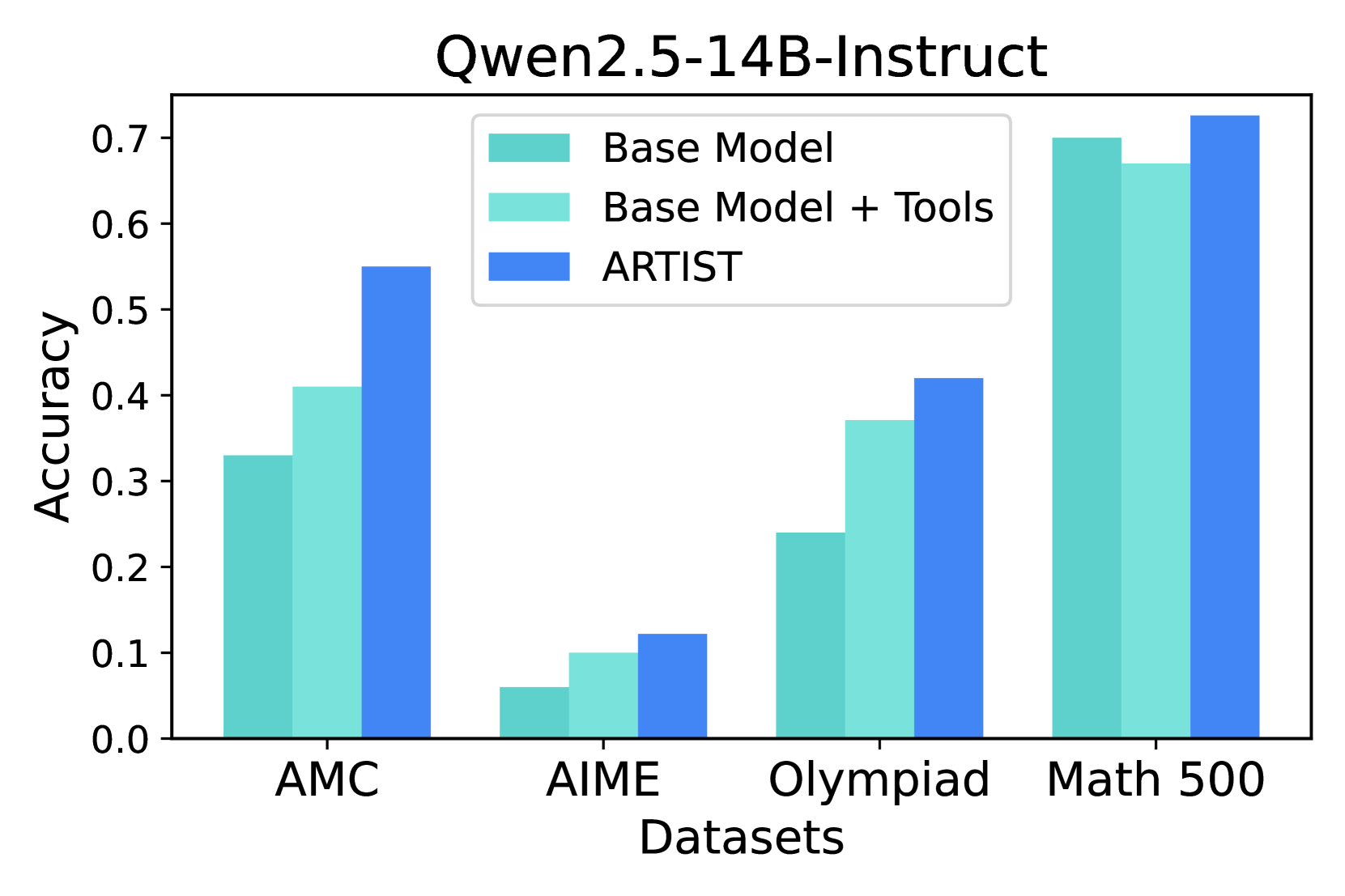
## Bar Chart: Qwen2.5-14B-Instruct Accuracy on Math Datasets
### Overview
This bar chart compares the accuracy of three models – Base Model, Base Model + Tools, and ARTIST – on four different math datasets: AMC, AIME, Olympiad, and Math 500. Accuracy is measured on the y-axis, and the datasets are displayed on the x-axis.
### Components/Axes
* **Title:** Qwen2.5-14B-Instruct (top-center)
* **X-axis Label:** Datasets (bottom-center)
* **Y-axis Label:** Accuracy (left-center)
* **Legend:** Located in the top-left corner.
* Base Model (light teal)
* Base Model + Tools (light blue)
* ARTIST (dark blue)
* **Datasets (X-axis Markers):** AMC, AIME, Olympiad, Math 500.
### Detailed Analysis
The chart consists of four groups of three bars, one for each dataset and model combination.
**AMC Dataset:**
* Base Model: Approximately 0.41 accuracy.
* Base Model + Tools: Approximately 0.53 accuracy.
* ARTIST: Approximately 0.55 accuracy.
*Trend:* All three models show positive accuracy, with ARTIST and Base Model + Tools performing better than the Base Model.
**AIME Dataset:**
* Base Model: Approximately 0.08 accuracy.
* Base Model + Tools: Approximately 0.09 accuracy.
* ARTIST: Approximately 0.11 accuracy.
*Trend:* Accuracy is significantly lower for all models on the AIME dataset compared to the AMC dataset. ARTIST performs best, but the difference between the models is smaller.
**Olympiad Dataset:**
* Base Model: Approximately 0.27 accuracy.
* Base Model + Tools: Approximately 0.29 accuracy.
* ARTIST: Approximately 0.32 accuracy.
*Trend:* Accuracy is higher than AIME but lower than AMC. ARTIST consistently outperforms the other two models.
**Math 500 Dataset:**
* Base Model: Approximately 0.68 accuracy.
* Base Model + Tools: Approximately 0.71 accuracy.
* ARTIST: Approximately 0.73 accuracy.
*Trend:* The highest accuracy scores are observed on the Math 500 dataset. ARTIST again shows the highest performance, followed closely by Base Model + Tools.
### Key Observations
* ARTIST consistently outperforms both the Base Model and the Base Model + Tools across all datasets.
* The Base Model + Tools generally performs better than the Base Model alone.
* Accuracy varies significantly depending on the dataset, with the Math 500 dataset yielding the highest scores and the AIME dataset the lowest.
* The performance gap between the models is most pronounced on the AMC and Math 500 datasets.
### Interpretation
The data suggests that the ARTIST model is the most effective at solving math problems across the tested datasets. The addition of tools to the Base Model provides a moderate improvement in accuracy. The varying performance across datasets indicates that the difficulty and nature of the problems within each dataset influence the models' ability to solve them. The Math 500 dataset, with its higher accuracy scores, may contain problems that are more aligned with the models' training data or capabilities. The AIME dataset, with its lower scores, may present unique challenges. The consistent outperformance of ARTIST suggests that its architecture or training methodology is particularly well-suited for tackling these types of math problems. The data demonstrates a clear hierarchy of performance: ARTIST > Base Model + Tools > Base Model. This could be due to the ARTIST model's ability to leverage more complex reasoning or problem-solving strategies.