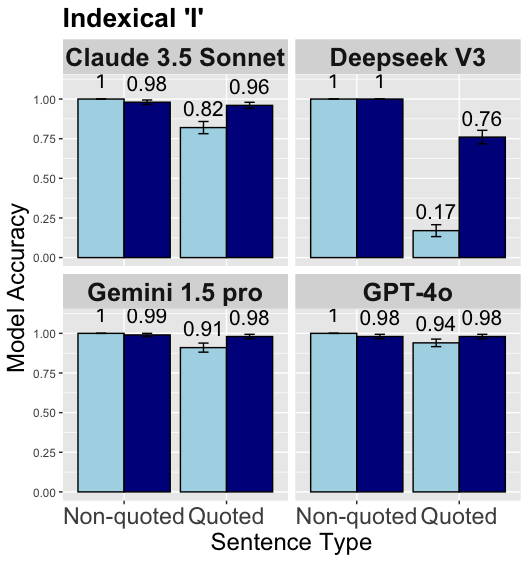
## Bar Chart: Indexical 'I' Model Accuracy
### Overview
The image is a bar chart comparing the model accuracy of four different language models (Claude 3.5 Sonnet, Deepseek V3, Gemini 1.5 pro, and GPT-4o) on "Indexical 'I'" sentences. The chart compares the accuracy on non-quoted and quoted sentences. The y-axis represents "Model Accuracy," ranging from 0.00 to 1.00. The x-axis represents "Sentence Type," with categories "Non-quoted" and "Quoted." Error bars are present on each bar, indicating variability in the data.
### Components/Axes
* **Title:** Indexical 'I'
* **Y-axis:** Model Accuracy, ranging from 0.00 to 1.00 in increments of 0.25.
* **X-axis:** Sentence Type, with two categories: Non-quoted and Quoted.
* **Models:**
* Claude 3.5 Sonnet (top-left)
* Deepseek V3 (top-right)
* Gemini 1.5 pro (bottom-left)
* GPT-4o (bottom-right)
* **Bar Colors:**
* Light Blue: Non-quoted sentences
* Dark Blue: Quoted sentences
### Detailed Analysis
**Claude 3.5 Sonnet:**
* Non-quoted: Accuracy of 1.00
* Quoted: Accuracy of 0.96, with an error bar indicating a range of approximately +/- 0.04.
**Deepseek V3:**
* Non-quoted: Accuracy of 1.00
* Quoted: Accuracy of 0.76, with an error bar indicating a range of approximately +/- 0.05.
**Gemini 1.5 pro:**
* Non-quoted: Accuracy of 1.00
* Quoted: Accuracy of 0.98, with an error bar indicating a range of approximately +/- 0.03.
**GPT-4o:**
* Non-quoted: Accuracy of 0.98, with an error bar indicating a range of approximately +/- 0.04.
* Quoted: Accuracy of 0.98, with an error bar indicating a range of approximately +/- 0.04.
### Key Observations
* All models perform well on non-quoted sentences, with accuracy close to 1.00.
* Deepseek V3 shows a significant drop in accuracy for quoted sentences (0.76) compared to non-quoted sentences (1.00).
* Gemini 1.5 pro maintains high accuracy for both non-quoted (1.00) and quoted (0.98) sentences.
* Claude 3.5 Sonnet and GPT-4o also show high accuracy for both sentence types, with a slight decrease in accuracy for quoted sentences.
* The error bars suggest some variability in the accuracy measurements, but the overall trends are clear.
### Interpretation
The chart suggests that the language models generally perform well on sentences involving "Indexical 'I'," but some models struggle with quoted sentences. Deepseek V3 appears to be particularly sensitive to the presence of quotes, showing a substantial decrease in accuracy. Gemini 1.5 pro demonstrates the most consistent performance across both sentence types. The differences in accuracy may be related to how each model handles the complexities of quoted speech and the context surrounding the indexical pronoun "I." The error bars indicate that the reported accuracy values are estimates with some degree of uncertainty.