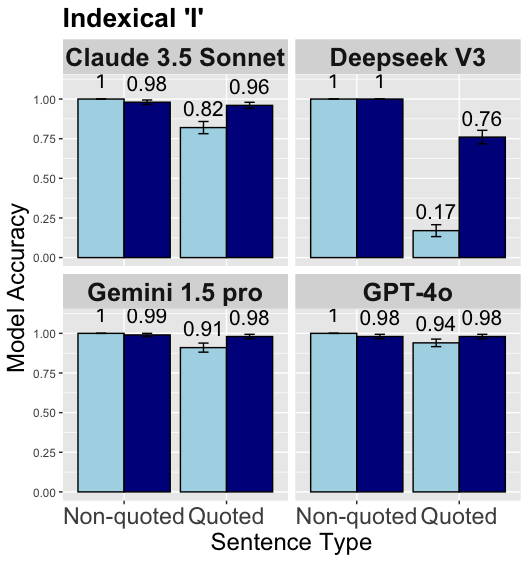
## Bar Chart: Indexical "I" Model Accuracy
### Overview
This image presents a bar chart comparing the model accuracy of four different language models – Claude 3.5 Sonnet, Deepseek V3, Gemini 1.5 pro, and GPT-4o – on two types of sentences: "Non-quoted" and "Quoted". Each bar represents the model accuracy, with error bars indicating the variance. The chart is organized as a 2x2 grid, with each quadrant dedicated to a specific model.
### Components/Axes
* **Title:** "Indexical 'I'"
* **Y-axis:** "Model Accuracy" (Scale ranges from 0.00 to 1.00)
* **X-axis:** "Sentence Type" with categories "Non-quoted" and "Quoted".
* **Models:** Claude 3.5 Sonnet, Deepseek V3, Gemini 1.5 pro, GPT-4o.
* **Color Scheme:** Dark blue for "Non-quoted" sentences, light blue/grey for "Quoted" sentences. Error bars are black.
### Detailed Analysis
The chart is divided into four sub-charts, one for each model.
**1. Claude 3.5 Sonnet (Top-Left)**
* **Non-quoted:** Accuracy is approximately 0.98, with a value of 1 displayed above the bar. Error bar extends from approximately 0.95 to 1.0.
* **Quoted:** Accuracy is approximately 0.82, with a value of 0.82 displayed above the bar. Error bar extends from approximately 0.78 to 0.86.
**2. Deepseek V3 (Top-Right)**
* **Non-quoted:** Accuracy is approximately 1.0, with a value of 1 displayed above the bar. Error bar is very small, extending from approximately 0.98 to 1.02.
* **Quoted:** Accuracy is approximately 0.17, with a value of 0.17 displayed above the bar. Error bar extends from approximately 0.15 to 0.19.
**3. Gemini 1.5 pro (Bottom-Left)**
* **Non-quoted:** Accuracy is approximately 0.99, with a value of 0.99 displayed above the bar. Error bar extends from approximately 0.97 to 1.0.
* **Quoted:** Accuracy is approximately 0.91, with a value of 0.91 displayed above the bar. Error bar extends from approximately 0.88 to 0.94.
**4. GPT-4o (Bottom-Right)**
* **Non-quoted:** Accuracy is approximately 0.98, with a value of 0.98 displayed above the bar. Error bar extends from approximately 0.96 to 1.0.
* **Quoted:** Accuracy is approximately 0.94, with a value of 0.94 displayed above the bar. Error bar extends from approximately 0.92 to 0.96.
### Key Observations
* Deepseek V3 exhibits a significant drop in accuracy when processing "Quoted" sentences compared to "Non-quoted" sentences.
* Claude 3.5 Sonnet, Gemini 1.5 pro, and GPT-4o maintain relatively high accuracy for both sentence types, though accuracy is generally lower for "Quoted" sentences.
* GPT-4o and Gemini 1.5 pro show the least performance difference between the two sentence types.
* The values displayed above the bars (1, 0.98, 0.99) appear to be rounded values, while the error bars suggest more precise underlying data.
### Interpretation
The data suggests that the ability of language models to accurately process sentences containing direct quotes (indexical "I") varies considerably. Deepseek V3 struggles significantly with quoted sentences, indicating a potential weakness in handling context or pronoun resolution within quoted speech. The other models demonstrate more robust performance, but still show a slight decrease in accuracy when dealing with quoted sentences. This could be due to the complexities of identifying the referent of "I" when it appears within a quoted statement. The error bars indicate the variability in the model's performance, suggesting that the accuracy scores are not always consistent. The fact that the values displayed above the bars are rounded to the nearest whole number or hundredth suggests that the underlying data may have more granularity than is presented in the chart. The chart highlights the importance of evaluating language models on a variety of linguistic constructions to identify potential weaknesses and areas for improvement.