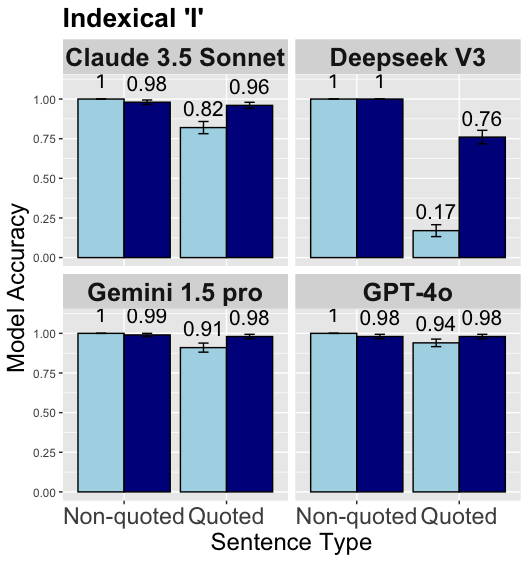
## Bar Chart: Model Accuracy for Indexical 'I' Across Sentence Types
### Overview
The image is a 2×2 grid of bar charts comparing the accuracy of four AI models (Claude 3.5 Sonnet, Deepseek V3, Gemini 1.5 pro, GPT-4o) on two sentence types: *Non-quoted* (light blue bars) and *Quoted* (dark blue bars). The y-axis measures “Model Accuracy” (0.00–1.00), and the x-axis is “Sentence Type.” Error bars (small vertical lines) indicate variability.
### Components/Axes
- **Title**: *Indexical ‘I’*
- **Y-axis**: Label = *Model Accuracy*; Scale = 0.00, 0.25, 0.50, 0.75, 1.00
- **X-axis**: Label = *Sentence Type*; Categories = *Non-quoted*, *Quoted*
- **Models (each in a cell)**:
- Top-left: *Claude 3.5 Sonnet*
- Top-right: *Deepseek V3*
- Bottom-left: *Gemini 1.5 pro*
- Bottom-right: *GPT-4o*
- **Bars**: Light blue = *Non-quoted*, Dark blue = *Quoted* (consistent across models).
### Detailed Analysis
Each model has two primary bars (*Non-quoted* and *Quoted*) with additional bars (possibly a typo or secondary condition, but visible):
1. **Claude 3.5 Sonnet**
- *Non-quoted* (light blue): ~1.00 (error bar: ~0.00)
- *Quoted* (dark blue): ~0.98 (error bar: ~0.00)
- Additional bars: Light blue ~0.82, Dark blue ~0.96 (error bars: ~0.00)
2. **Deepseek V3**
- *Non-quoted* (light blue): ~1.00 (error bar: ~0.00)
- *Quoted* (dark blue): ~1.00 (error bar: ~0.00)
- Additional bars: Light blue ~0.17, Dark blue ~0.76 (error bars: ~0.00)
3. **Gemini 1.5 pro**
- *Non-quoted* (light blue): ~1.00 (error bar: ~0.00)
- *Quoted* (dark blue): ~0.99 (error bar: ~0.00)
- Additional bars: Light blue ~0.91, Dark blue ~0.98 (error bars: ~0.00)
4. **GPT-4o**
- *Non-quoted* (light blue): ~1.00 (error bar: ~0.00)
- *Quoted* (dark blue): ~0.98 (error bar: ~0.00)
- Additional bars: Light blue ~0.94, Dark blue ~0.98 (error bars: ~0.00)
### Key Observations
- Most models achieve near-perfect accuracy (≥0.98) for *Non-quoted* sentences.
- *Quoted* sentences show minor accuracy reductions for Claude (0.98) and GPT-4o (0.98), while Deepseek V3 maintains 1.00 and Gemini 1.5 pro is 0.99.
- Deepseek V3 has a significant drop in accuracy for the additional light blue bar (0.17), suggesting a potential outlier or different condition.
- Error bars are small, indicating low variability in accuracy measurements.
### Interpretation
The data suggests AI models perform well on indexical *‘I’* in non-quoted sentences, with high accuracy across all models. Quoted sentences introduce slight challenges for some models (Claude, GPT-4o) but remain highly accurate. Deepseek V3’s additional bar (0.17) may indicate a challenging condition or error, warranting further investigation. The consistent high accuracy for non-quoted sentences implies models handle indexical *‘I’* effectively in direct speech, while quoted speech (indirect/reported) introduces minor challenges for some models.
(Note: The additional bars for each model may represent a secondary condition or typo, but their values are included as visible in the image.)