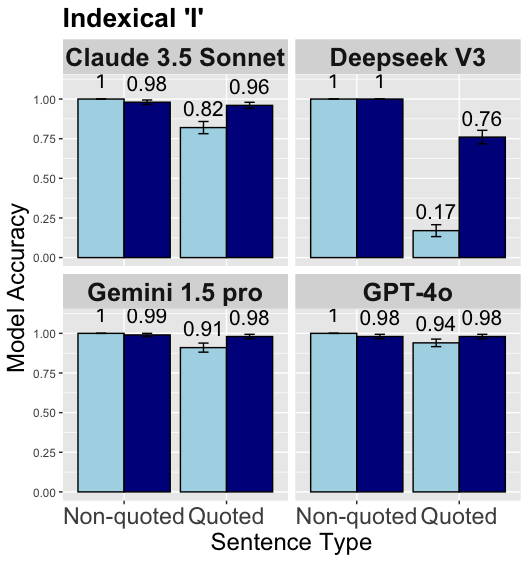
## Bar Chart: Indexical 'I' Model Accuracy Comparison
### Overview
The chart compares model accuracy across four AI systems (Claude 3.5 Sonnet, Deepseek V3, Gemini 1.5 Pro, GPT-4o) for two sentence types: Non-quoted and Quoted. Accuracy is measured on a 0.00-1.00 scale with error bars indicating variability.
### Components/Axes
- **X-axis**: Sentence Type (Non-quoted, Quoted)
- **Y-axis**: Model Accuracy (0.00-1.00 scale)
- **Legend**:
- Light blue = Non-quoted
- Dark blue = Quoted
- **Quadrants**: Four model-specific sub-charts arranged in 2x2 grid
### Detailed Analysis
1. **Claude 3.5 Sonnet**
- Non-quoted: 0.98 ±0.02
- Quoted: 0.96 ±0.04
2. **Deepseek V3**
- Non-quoted: 0.98 ±0.02
- Quoted: 0.76 ±0.04
3. **Gemini 1.5 Pro**
- Non-quoted: 0.99 ±0.01
- Quoted: 0.98 ±0.02
4. **GPT-4o**
- Non-quoted: 0.98 ±0.02
- Quoted: 0.94 ±0.04
### Key Observations
1. **Non-quoted superiority**: All models show higher accuracy for non-quoted sentences (range: 0.94-0.99 vs. 0.76-0.98 for quoted)
2. **Deepseek V3 anomaly**: Only model where quoted accuracy (0.76) significantly lags behind non-quoted (0.98)
3. **Error patterns**:
- Quoted errors generally larger (±0.02-0.04 vs. ±0.01-0.02 for non-quoted)
- Gemini 1.5 Pro shows smallest error margins overall
4. **Consistency**: All models maintain ≥0.94 accuracy in non-quoted sentences
### Interpretation
The data demonstrates a clear trend where AI models perform better on non-quoted sentences across all tested systems. Deepseek V3's dramatic drop in quoted accuracy (22% relative decrease) suggests potential architectural differences in handling quoted content. The minimal error margins (≤0.04) indicate high reliability in measurements, with Gemini 1.5 Pro showing the most consistent performance. This pattern may reflect challenges in contextual interpretation when dealing with quoted material versus direct statements.