TECHNICAL ASSET FINGERPRINT
628b49016583ffedfb331fe9
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
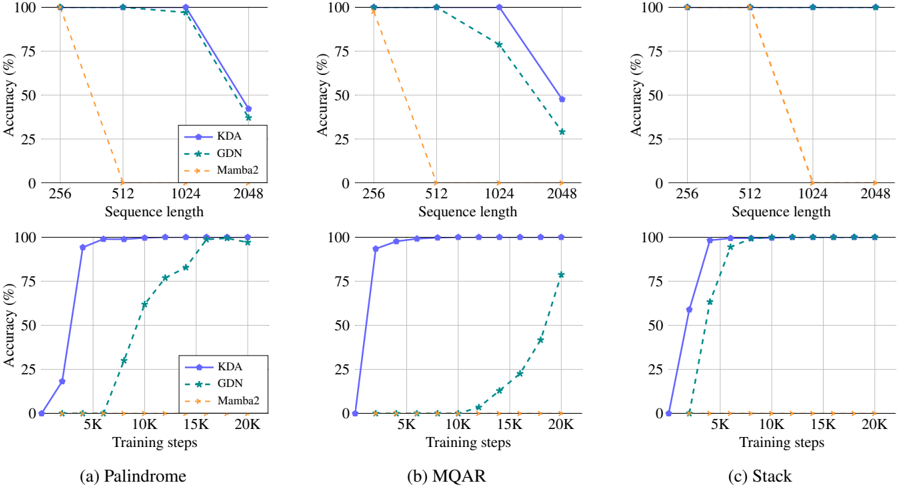
## Multi-Panel Line Chart: Model Accuracy Comparison Across Tasks
### Overview
The image is a composite figure containing six line charts arranged in a 2x3 grid. It compares the performance of three models—KDA, GDN, and Mamba2—on three distinct tasks: Palindrome, MQAR, and Stack. The top row of charts plots model accuracy against increasing sequence length, while the bottom row plots accuracy against increasing training steps. The overall purpose is to evaluate and contrast the scalability and learning efficiency of the models.
### Components/Axes
* **Layout:** A 2-row by 3-column grid of subplots.
* **Subplot Titles/Captions:** Located below each column.
* (a) Palindrome (Left column)
* (b) MQAR (Center column)
* (c) Stack (Right column)
* **Y-Axis (All Charts):** Labeled "Accuracy (%)". Scale ranges from 0 to 100, with major tick marks at 0, 25, 50, 75, and 100.
* **X-Axis (Top Row Charts):** Labeled "Sequence length". Discrete tick marks at 256, 512, 1024, and 2048.
* **X-Axis (Bottom Row Charts):** Labeled "Training steps". Discrete tick marks at 5K, 10K, 15K, and 20K.
* **Legend:** Present in the top-right corner of the top-left and bottom-left charts. It is consistent across all six charts.
* **KDA:** Blue solid line with circle markers.
* **GDN:** Green dashed line with star markers.
* **Mamba2:** Orange dashed line with 'x' markers.
### Detailed Analysis
#### **Top Row: Accuracy vs. Sequence Length**
* **Trend Verification:** For all tasks, the KDA (blue) and GDN (green) lines generally slope downward as sequence length increases, indicating decreasing accuracy. The Mamba2 (orange) line shows a very steep, near-vertical drop to 0% accuracy at relatively short sequence lengths.
**(a) Palindrome - Sequence Length**
* **KDA (Blue):** Starts at ~100% accuracy at length 256. Maintains near 100% at 512 and 1024. Drops sharply to approximately 40% at length 2048.
* **GDN (Green):** Follows a nearly identical path to KDA, starting at ~100% and dropping to approximately 35% at length 2048.
* **Mamba2 (Orange):** Starts at ~100% at length 256. Drops precipitously to 0% at length 512 and remains at 0% for 1024 and 2048.
**(b) MQAR - Sequence Length**
* **KDA (Blue):** Starts at 100% at length 256. Maintains 100% at 512. Drops to approximately 80% at 1024 and further to approximately 45% at 2048.
* **GDN (Green):** Starts at 100% at length 256. Drops to approximately 80% at 512, then to approximately 75% at 1024, and finally to approximately 30% at 2048.
* **Mamba2 (Orange):** Starts at 100% at length 256. Drops to 0% at length 512 and remains at 0% for longer sequences.
**(c) Stack - Sequence Length**
* **KDA (Blue):** Maintains a flat line at 100% accuracy across all sequence lengths (256 to 2048).
* **GDN (Green):** Also maintains a flat line at 100% accuracy across all sequence lengths.
* **Mamba2 (Orange):** Starts at 100% at length 256. Drops to 0% at length 512 and remains at 0% for longer sequences.
#### **Bottom Row: Accuracy vs. Training Steps**
* **Trend Verification:** For KDA and GDN, the lines slope upward, showing improved accuracy with more training steps. The Mamba2 line remains flat at or near 0% across all training steps shown.
**(a) Palindrome - Training Steps**
* **KDA (Blue):** Starts near 0% at the earliest measured step. Rises sharply to approximately 95% by 5K steps. Reaches and maintains ~100% from 10K to 20K steps.
* **GDN (Green):** Starts near 0%. Begins rising after 5K steps, reaching approximately 30% at 10K, 80% at 15K, and ~100% at 20K steps.
* **Mamba2 (Orange):** Remains at approximately 0% across all training steps (5K to 20K).
**(b) MQAR - Training Steps**
* **KDA (Blue):** Starts near 0%. Rises very sharply to approximately 95% by 5K steps. Reaches and maintains ~100% from 10K to 20K steps.
* **GDN (Green):** Starts near 0%. Remains near 0% until after 10K steps. Shows a gradual rise to approximately 15% at 15K steps, then a sharp increase to approximately 80% at 20K steps.
* **Mamba2 (Orange):** Remains at approximately 0% across all training steps.
**(c) Stack - Training Steps**
* **KDA (Blue):** Starts near 0%. Rises to approximately 60% by 5K steps. Reaches ~100% by 10K steps and maintains it.
* **GDN (Green):** Starts near 0%. Rises to approximately 65% by 5K steps, then to ~100% by 10K steps, maintaining it thereafter.
* **Mamba2 (Orange):** Remains at approximately 0% across all training steps.
### Key Observations
1. **Model Hierarchy:** KDA consistently demonstrates the best or tied-for-best performance, followed by GDN. Mamba2 performs catastrophically poorly on all tasks beyond the shortest sequence length or with the given training budget.
2. **Task Difficulty:** The "Stack" task appears to be the easiest for KDA and GDN, as they achieve perfect accuracy across all sequence lengths and converge quickly during training. "Palindrome" and "MQAR" show more pronounced performance degradation with longer sequences.
3. **Sequence Length Sensitivity:** Both KDA and GDN are sensitive to very long sequences (2048) on the Palindrome and MQAR tasks, with significant accuracy drops. Mamba2 is extremely sensitive, failing completely at sequence length 512.
4. **Learning Speed:** KDA learns the fastest, reaching near-perfect accuracy within 5K training steps on all tasks. GDN learns more slowly, particularly on MQAR where it shows minimal progress until after 10K steps.
5. **Performance Ceiling:** On the Stack task, KDA and GDN hit a clear performance ceiling of 100% accuracy, which they maintain.
### Interpretation
This data strongly suggests a significant performance advantage for the KDA and GDN architectures over Mamba2 on the evaluated algorithmic reasoning tasks (Palindrome, MQAR, Stack). The near-total failure of Mamba2 indicates a fundamental limitation in its ability to handle these specific types of sequential, state-dependent computations, especially as problem complexity (sequence length) increases.
The contrast between the top and bottom rows is informative. The top row shows the *limits* of each model's generalization to longer sequences after training. The bottom row shows the *learning dynamics* during training on a fixed (presumably shorter) sequence length. KDA's rapid convergence suggests it has an inductive bias well-suited to these tasks. GDN's slower but eventual convergence, especially on Stack and Palindrome, shows it can learn the tasks but requires more data/updates. Mamba2's flatline at 0% in the training curves suggests it fails to learn the tasks at all within the given training budget, which correlates with its inability to generalize to longer sequences.
The outlier is the Stack task, where KDA and GDN show no degradation with sequence length. This implies the Stack task may rely on a more local or consistent pattern that these models can capture perfectly, unlike the potentially more globally dependent patterns in Palindrome and MQAR. The investigation points toward KDA as the most robust and efficient model among the three for this class of problems.
DECODING INTELLIGENCE...