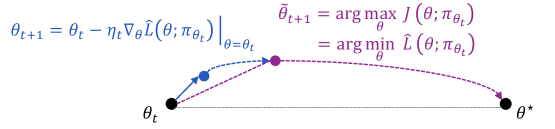
## Diagram: Optimization Process
### Overview
The image illustrates an optimization process, likely related to machine learning or a similar field. It shows the iterative steps of updating a parameter θ to reach an optimal value θ*. The diagram uses arrows and equations to represent the update rules and the search for the optimal value.
### Components/Axes
* **Nodes:**
* θt: Initial parameter value (black dot)
* Intermediate point (blue dot)
* θ̃t+1: Intermediate parameter value (purple dot)
* θ*: Optimal parameter value (black dot)
* **Arrows:**
* Blue arrow: Represents the gradient descent step.
* Purple dashed arrow: Represents the optimization step to find θ̃t+1.
* Dashed gray line: Represents the direct path from θt to θ*.
* **Equations:**
* θt+1 = θt - ηt∇θL̂(θ; πθt)|θ=θt (Blue text, top-left)
* θ̃t+1 = arg maxθ J(θ; πθt) = arg minθ L̂(θ; πθt) (Purple text, top-right)
### Detailed Analysis
* **Initial State (θt):** The process starts at θt, represented by a black dot on the left.
* **Gradient Descent Step (Blue):** A blue arrow originates from θt, indicating a step in the direction of the negative gradient of the loss function L̂. The equation θt+1 = θt - ηt∇θL̂(θ; πθt)|θ=θt describes this update, where ηt is the learning rate and ∇θL̂(θ; πθt) is the gradient of the loss function with respect to θ, evaluated at θt. This step leads to an intermediate blue dot.
* **Optimization Step (Purple):** A purple dashed arrow originates from the blue dot and curves upwards to a purple dot labeled θ̃t+1. This represents an optimization step to find the best θ given the current policy πθt. The equation θ̃t+1 = arg maxθ J(θ; πθt) = arg minθ L̂(θ; πθt) describes this step, where J is a reward function and L̂ is a loss function.
* **Optimal State (θ*):** A purple dashed arrow originates from θ̃t+1 and curves downwards to the final black dot labeled θ*. This represents the final step in the optimization process, aiming to reach the optimal parameter value θ*.
* **Direct Path (Gray):** A dashed gray line connects θt directly to θ*, representing the ideal, but often unattainable, direct path to the optimal value.
### Key Observations
* The diagram illustrates an iterative optimization process.
* The process involves both gradient descent and a separate optimization step.
* The goal is to find the optimal parameter value θ*.
### Interpretation
The diagram depicts a two-stage optimization process. The blue arrow represents a gradient descent step, which moves the parameter θ in the direction of decreasing loss. The purple arrow represents a more sophisticated optimization step, which aims to find the best θ given the current policy. This could represent a policy improvement step in reinforcement learning, where the policy is updated to maximize the expected reward. The dashed gray line represents the ideal, but often unattainable, direct path to the optimal value. The diagram highlights the iterative nature of the optimization process and the interplay between gradient descent and policy optimization.