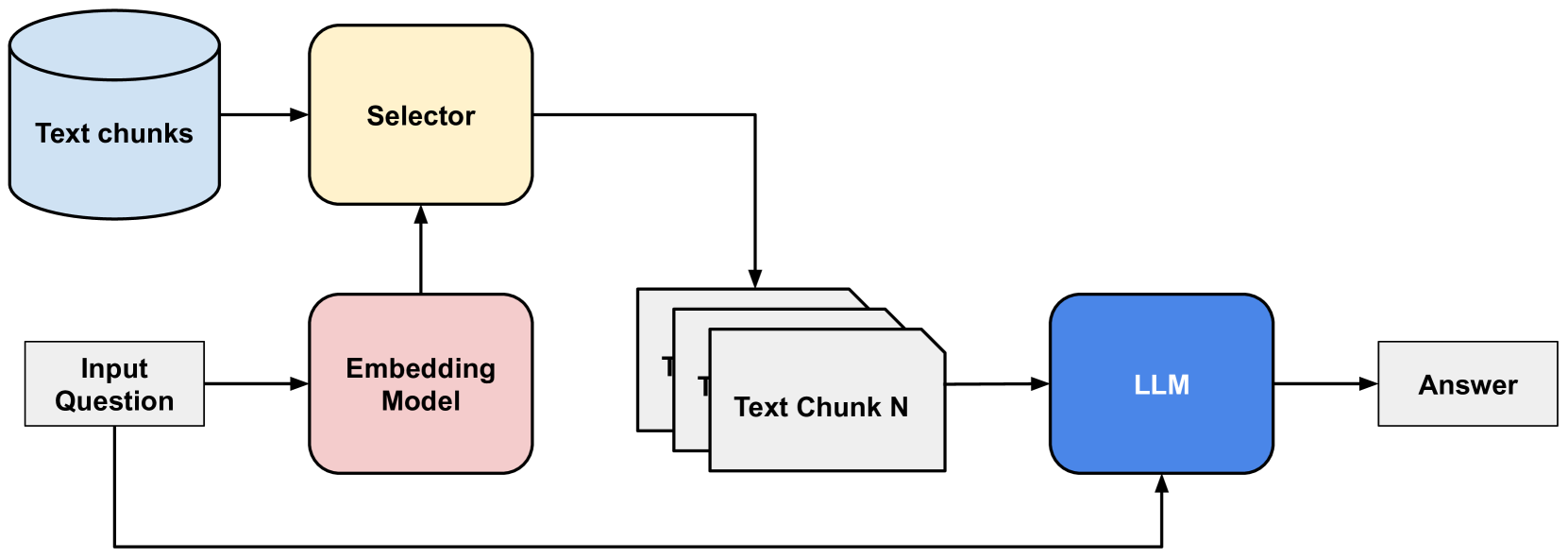
## Flowchart: Retrieval-Augmented Generation System
### Overview
The diagram illustrates a technical workflow for generating answers from a text database using a combination of embedding models, a selector, and a large language model (LLM). The process begins with an input question, progresses through text retrieval and processing, and concludes with an answer generation step that feeds back into the system.
### Components/Axes
1. **Text Chunks Database** (Blue Cylinder):
- Position: Top-left
- Label: "Text chunks"
- Color: Light blue
2. **Selector** (Yellow Square):
- Position: Top-center
- Label: "Selector"
- Color: Yellow
3. **Embedding Model** (Pink Square):
- Position: Bottom-left
- Label: "Embedding Model"
- Color: Pink
4. **LLM** (Blue Square):
- Position: Bottom-right
- Label: "LLM"
- Color: Blue
5. **Answer** (White Rectangle):
- Position: Far-right
- Label: "Answer"
- Color: White
**Arrows**:
- Black arrows indicate directional flow between components.
- Feedback loop: Answer → Input Question (dashed arrow).
### Detailed Analysis
- **Input Question** (White Rectangle):
- Position: Bottom-left, connected to Embedding Model.
- Role: Initiates the process.
- **Embedding Model**:
- Converts the input question into embeddings (vector representations).
- Outputs to the Selector.
- **Selector**:
- Receives embeddings and queries the Text Chunks Database.
- Outputs "Text Chunk N" (generic placeholder for retrieved text).
- **Text Chunks Database**:
- Contains multiple text chunks (N instances shown as stacked rectangles).
- Position: Top-center, connected to Selector and LLM.
- **LLM**:
- Processes retrieved text chunks to generate an answer.
- Outputs to the Answer block.
- **Answer**:
- Final output of the system.
- Feedback loop returns to Input Question for iterative refinement.
### Key Observations
1. **Modular Architecture**:
- Components are decoupled (e.g., Selector and LLM operate independently).
2. **Feedback Mechanism**:
- Answer re-enters the system, suggesting iterative improvement.
3. **Color Coding**:
- Blue (Text Chunks, LLM) and Pink (Embedding Model) distinguish data storage (blue) from processing units (pink/yellow).
4. **Simplified Representation**:
- Text Chunks Database is abstracted as a single cylinder despite containing multiple chunks.
### Interpretation
This flowchart represents a **Retrieval-Augmented Generation (RAG)** pipeline, where:
- The **Embedding Model** bridges natural language questions and the text database by converting queries into vector embeddings.
- The **Selector** acts as a retrieval mechanism, fetching contextually relevant text chunks based on embeddings.
- The **LLM** synthesizes the retrieved text with the original question to generate a context-aware answer.
- The feedback loop implies the system can refine answers by re-processing the input question with updated embeddings or additional text chunks.
**Technical Implications**:
- The architecture emphasizes scalability (modular components) and accuracy (contextual retrieval).
- The absence of explicit evaluation metrics (e.g., precision/recall) suggests this is a high-level design rather than a performance benchmark.
- The feedback loop hints at potential for dynamic adaptation, though its implementation details (e.g., retraining, re-embedding) are unspecified.