## System Architecture Diagram: Retrieval-Augmented Generation (RAG) Pipeline
### Overview
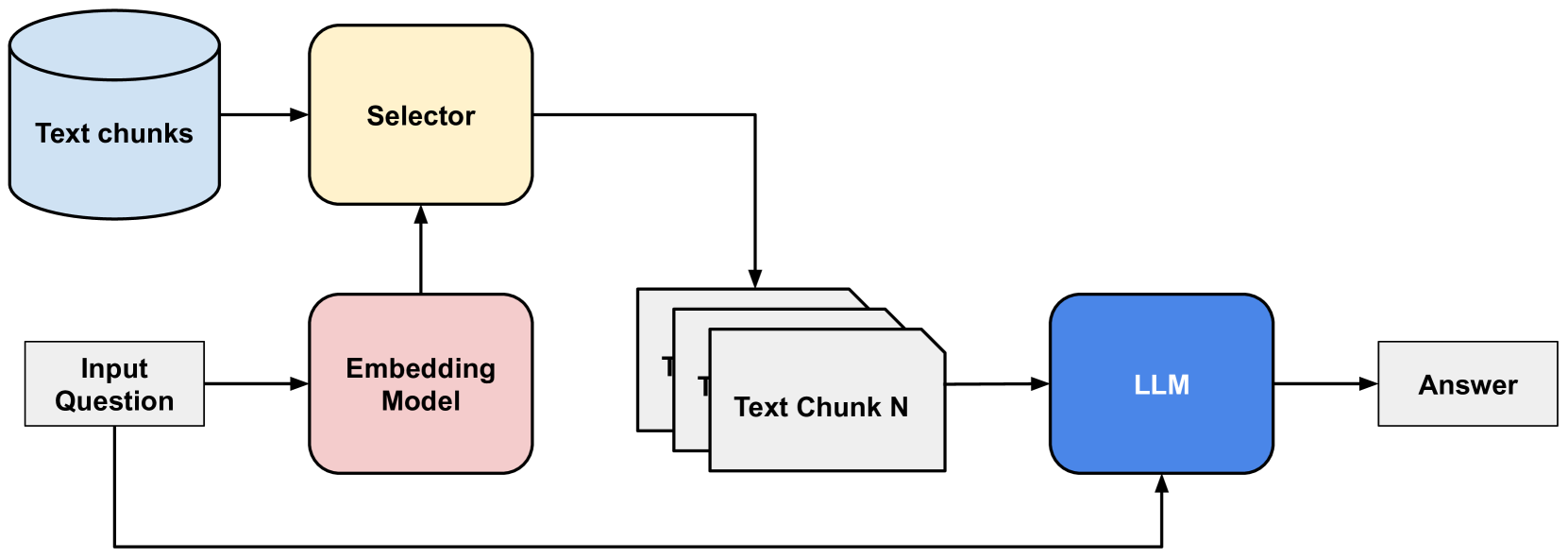
The image displays a technical flowchart illustrating a Retrieval-Augmented Generation (RAG) system architecture. It depicts the process flow from an input question to a generated answer, involving text chunk storage, embedding, selection, and a Large Language Model (LLM). The diagram uses color-coded shapes and directional arrows to represent components and data flow.
### Components
The diagram consists of seven primary components connected by directional arrows indicating data flow. All text is in English.
1. **Text chunks** (Top-Left): Represented by a light blue cylinder icon, symbolizing a database or vector store.
2. **Selector** (Top-Center): A yellow rounded rectangle.
3. **Input Question** (Bottom-Left): A white rectangle.
4. **Embedding Model** (Bottom-Left, right of Input Question): A pink rounded rectangle.
5. **Text Chunk N** (Center-Right): A stack of three white rectangles, with the front one labeled. The label "Text Chunk N" implies multiple chunks (1 through N) are involved.
6. **LLM** (Right): A blue rounded rectangle.
7. **Answer** (Far-Right): A white rectangle.
### Detailed Analysis
The process flow, as indicated by the arrows, is as follows:
1. **Data Storage & Retrieval Initiation**:
* The "Text chunks" database provides input to the "Selector" component.
* The "Input Question" is fed into the "Embedding Model".
2. **Question Processing & Chunk Selection**:
* The "Embedding Model" processes the "Input Question" and sends its output (an embedding vector) to the "Selector".
* The "Selector" uses this embedding to query the "Text chunks" database and retrieves relevant chunks. The output of the Selector is a set of relevant text chunks, represented by the stack labeled "Text Chunk N".
3. **Answer Generation**:
* The selected "Text Chunk N" is sent as context to the "LLM".
* Crucially, a separate arrow also sends the original "Input Question" directly to the "LLM". This indicates the LLM receives both the retrieved context and the original query.
* The "LLM" processes this combined input and produces the final "Answer".
### Key Observations
* **Dual Input to LLM**: The LLM receives two distinct inputs: the retrieved text chunks (context) and the original input question. This is a standard pattern in RAG systems to ensure the answer is grounded in the provided documents while addressing the specific query.
* **Component Roles**: The color coding suggests functional grouping: storage (blue cylinder), processing/selection (yellow, pink), data (white rectangles), and the core generative model (blue rectangle).
* **Abstraction**: The diagram is high-level. It abstracts away details like the specific embedding algorithm, the selection mechanism (e.g., similarity search), the LLM's architecture, and the format of the text chunks.
### Interpretation
This diagram visually explains the core mechanism of a Retrieval-Augmented Generation system. The data suggests a pipeline designed to overcome a key limitation of standalone LLMs: their static knowledge and tendency to "hallucinate."
* **How it works**: Instead of relying solely on its internal parameters, the system first *retrieves* relevant information ("Text chunks") from an external knowledge base based on the semantic meaning of the user's question (via the "Embedding Model" and "Selector"). It then *augments* the LLM's prompt with this retrieved context before *generating* an answer.
* **Purpose**: This architecture grounds the LLM's response in specific, verifiable source documents, improving factual accuracy, reducing hallucinations, and allowing the system to incorporate new information without retraining the core LLM.
* **Notable Design Choice**: The direct link from "Input Question" to "LLM" is critical. It ensures the model knows what to answer, while the link from "Text Chunk N" provides the factual basis for the answer. The "Selector" acts as the intelligent filter, determining which pieces of the vast "Text chunks" database are pertinent to the specific query.
**Language Declaration**: All text within the image is in English.