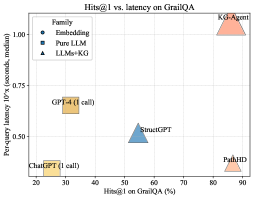
## Chart: Hits@1 vs. latency on GrailQA
### Overview
This chart plots the Hits@1 (accuracy) against the per-query latency for different models on the GrailQA dataset. The models are categorized into three families: Embedding, Pure LLM, and LLMs+KG. The chart visualizes the trade-off between accuracy and latency for each model.
### Components/Axes
* **Title:** Hits@1 vs. latency on GrailQA
* **X-axis:** Hits@1 on GrailQA (%)
* Scale: 20 to 90, with tick marks at intervals of 10.
* **Y-axis:** Per-query latency 10'x (seconds, median)
* Scale: 0.50 to 1.00, with tick marks at intervals of 0.25.
* **Legend (top-left):**
* Embedding (blue circle)
* Pure LLM (blue square)
* LLMs+KG (blue triangle)
### Detailed Analysis
* **Embedding:**
* There are no explicit data points for "Embedding" models on the chart.
* **Pure LLM:**
* ChatGPT (1 call): Located at approximately (22, 0.30). Color: Light Yellow.
* GPT-4 (1 call): Located at approximately (35, 0.65). Color: Light Yellow.
* **LLMs+KG:**
* StructGPT: Located at approximately (55, 0.52). Color: Light Blue.
* PathHD: Located at approximately (85, 0.35). Color: Light Orange.
* KG-Agent: Located at approximately (82, 1.02). Color: Light Orange.
### Key Observations
* The chart shows a distribution of models across different accuracy and latency levels.
* ChatGPT and GPT-4 (Pure LLM) have lower latency but also lower Hits@1 compared to other models.
* KG-Agent (LLMs+KG) has the highest latency and highest Hits@1.
* StructGPT (LLMs+KG) has a moderate latency and moderate Hits@1.
* PathHD (LLMs+KG) has a low latency and high Hits@1.
### Interpretation
The data suggests a trade-off between accuracy (Hits@1) and latency for question answering on the GrailQA dataset. Pure LLM models like ChatGPT and GPT-4 offer faster response times but lower accuracy. LLMs+KG models, such as KG-Agent, StructGPT, and PathHD, generally achieve higher accuracy but at the cost of increased latency. PathHD is a notable outlier, achieving high accuracy with relatively low latency. The choice of model depends on the specific application requirements, balancing the need for accurate answers with the acceptable response time.