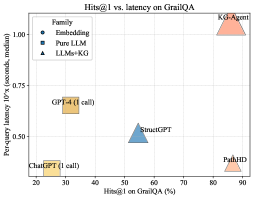
## Scatter Plot: H@1 vs. Latency on GraIL QA
### Overview
This image is a scatter plot comparing the performance of various AI models on the GraIL QA task. It plots model accuracy (H@1) against inference latency (95th percentile). The chart includes a legend categorizing models into three families: Fine-tuning, Pure LLM, and LLM+KG.
### Components/Axes
* **Chart Title:** "Hin@1 vs. latency on GraIL QA" (Note: "Hin@1" appears to be a typo or specific metric name, likely meaning "Hits@1").
* **X-Axis:** "Hin@1 on GraIL QA (%)". Scale ranges from 0 to 90, with major ticks at 0, 10, 20, 30, 40, 50, 60, 70, 80, 90.
* **Y-Axis:** "Percentile latency 95% (seconds median)". Scale ranges from 0.00 to 1.00, with major ticks at 0.00, 0.20, 0.40, 0.60, 0.80, 1.00.
* **Legend (Top-Left Corner):**
* **Family:**
* Fine-tuning (Orange square symbol)
* Pure LLM (Blue triangle symbol)
* LLM+KG (Pink triangle symbol)
* **Data Points (Models):** Each point is labeled with a model name and, for some, a note about the number of calls.
### Detailed Analysis
The plot contains five distinct data points, each representing a model. Their approximate coordinates (Hin@1 %, Latency seconds) are:
1. **ChatGPT (1 call)**
* **Family:** Fine-tuning (Orange square)
* **Position:** Bottom-left quadrant.
* **Approximate Values:** Hin@1 ≈ 15%, Latency ≈ 0.10 seconds.
* **Trend:** Lowest accuracy and lowest latency among the plotted models.
2. **GPT-4 (1 call)**
* **Family:** Fine-tuning (Orange square)
* **Position:** Left-center, above ChatGPT.
* **Approximate Values:** Hin@1 ≈ 25%, Latency ≈ 0.40 seconds.
* **Trend:** Higher accuracy and higher latency than ChatGPT.
3. **SimounGPT**
* **Family:** Pure LLM (Blue triangle)
* **Position:** Center of the plot.
* **Approximate Values:** Hin@1 ≈ 55%, Latency ≈ 0.50 seconds.
* **Trend:** Mid-range accuracy and latency.
4. **PahKD**
* **Family:** LLM+KG (Pink triangle)
* **Position:** Bottom-right quadrant.
* **Approximate Values:** Hin@1 ≈ 85%, Latency ≈ 0.20 seconds.
* **Trend:** High accuracy with relatively low latency.
5. **K-LoRAm**
* **Family:** LLM+KG (Pink triangle)
* **Position:** Top-right corner.
* **Approximate Values:** Hin@1 ≈ 90%, Latency ≈ 1.00 seconds.
* **Trend:** Highest accuracy but also the highest latency.
### Key Observations
* **Performance-Latency Trade-off:** There is a general, but not strict, positive correlation between accuracy (Hin@1) and latency. Models with higher accuracy tend to have higher latency.
* **Family Clustering:** Models from the same family (Fine-tuning, LLM+KG) tend to cluster in specific regions of the plot. Fine-tuning models are in the low-accuracy/low-latency region. LLM+KG models are in the high-accuracy region, but with divergent latency.
* **Notable Outlier:** **PahKD** (LLM+KG) is a significant outlier. It achieves very high accuracy (≈85%) with low latency (≈0.20s), breaking the general trend. This suggests a highly efficient architecture or method.
* **Latency Range:** Latencies vary by an order of magnitude, from ~0.1s (ChatGPT) to ~1.0s (K-LoRAm).
* **Accuracy Range:** Accuracy varies widely, from ~15% to ~90%.
### Interpretation
This chart visualizes the core engineering trade-off between model performance (accuracy) and computational cost (latency) for the GraIL QA task. The data suggests:
1. **Methodology Matters:** The "LLM+KG" (Large Language Model + Knowledge Graph) family demonstrates the potential for achieving state-of-the-art accuracy (PahKD, K-LoRAm). This implies that augmenting LLMs with structured knowledge is a powerful strategy for this QA task.
2. **Efficiency is Achievable:** The stark contrast between **PahKD** (high accuracy, low latency) and **K-LoRAm** (high accuracy, high latency) within the same family indicates that not all LLM+KG approaches are equal. PahKD likely represents a more optimized or efficient integration method, making it a more practical choice for real-time applications.
3. **Baseline Performance:** The "Fine-tuning" models (ChatGPT, GPT-4) serve as a baseline, showing that standard fine-tuning of general-purpose LLMs yields lower performance on this specialized task compared to knowledge-augmented approaches.
4. **Task-Specific Insight:** The GraIL QA task appears to benefit significantly from external knowledge (KG), as the top two performing models are from the LLM+KG family. The "Pure LLM" (SimounGPT) sits in the middle, suggesting its parametric knowledge alone is insufficient for top performance.
**In summary, the chart argues for the effectiveness of LLM+KG systems for complex QA, while highlighting that the specific implementation (as seen with PahKD) is critical for balancing accuracy with practical latency constraints.**