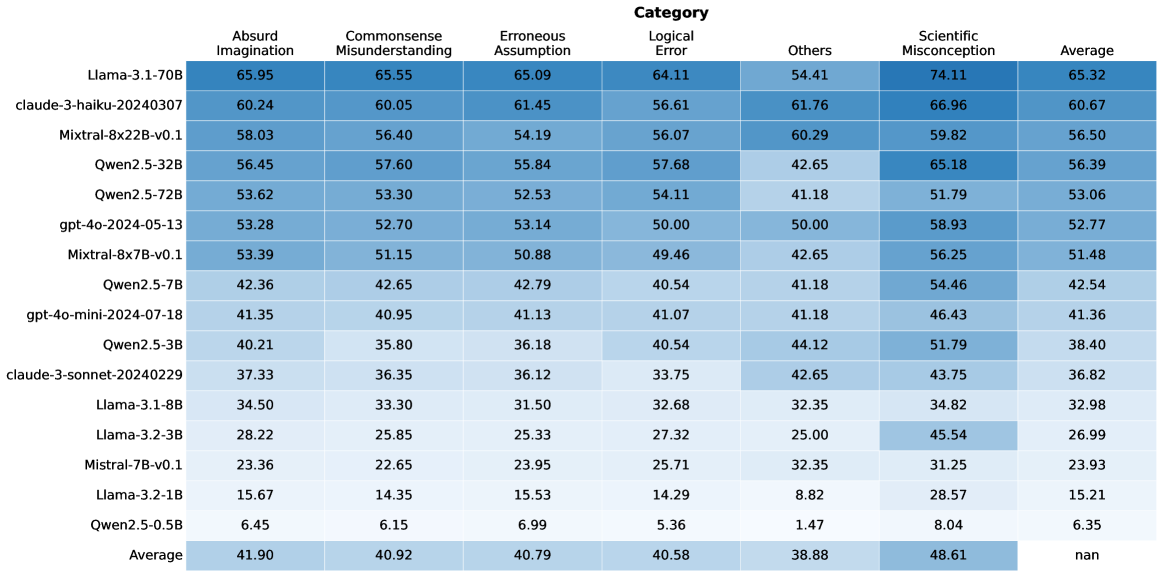
## Heatmap: Model Performance Across Cognitive Categories
### Overview
The heatmap visualizes performance metrics of various AI models across seven cognitive categories, with color-coded values representing scores. The average row at the bottom aggregates performance across all models.
### Components/Axes
- **X-axis (Categories)**:
- Absurd Imagination
- Commonsense Misunderstanding
- Erroneous Assumption
- Logical Error
- Others
- Scientific Misconception
- Average
- **Y-axis (Models)**:
- Llama-3.1-70B
- Claude-3-haiku-20240307
- Mistral-8x7B-v0.1
- Qwen2.5-32B
- Qwen2.5-72B
- gpt-4o-2024-05-13
- Qwen2.5-7B
- gpt-4o-mini-2024-07-18
- Qwen2.5-3B
- Claude-3-sonnet-20240229
- Llama-3.1-8B
- Llama-3.2-3B
- Mistral-7B-v0.1
- Llama-3.2-1B
- Qwen2.5-0.5B
- Average
- **Legend**:
- Blue shades represent categories (darker = higher values)
- Color gradient: Dark blue (high) → Light blue (low)
### Detailed Analysis
1. **Model Performance**:
- **Llama-3.1-70B**:
- Absurd Imagination: 65.95 (darkest blue)
- Scientific Misconception: 74.11 (darkest blue)
- **Claude-3-haiku-20240307**:
- Commonsense Misunderstanding: 60.05
- Logical Error: 61.76
- **Mistral-8x7B-v0.1**:
- Erroneous Assumption: 50.88
- Logical Error: 49.46
- **Average Row**:
- Scientific Misconception: 48.61 (highest)
- Logical Error: 40.58
- Commonsense Misunderstanding: 40.92
2. **Color Consistency**:
- All values match legend colors (e.g., 65.95 in dark blue for Absurd Imagination aligns with legend)
- Average row uses gray tones for neutral comparison
3. **Spatial Grounding**:
- Legend positioned right of chart
- Average row at bottom (gray background)
- Model names left-aligned, categories top-aligned
### Key Observations
1. **Highest Performance**:
- Scientific Misconception dominates (avg 48.61)
- Llama-3.1-70B excels in Absurd Imagination (65.95) and Scientific Misconception (74.11)
2. **Lowest Performance**:
- Logical Error shows weakest scores (avg 40.58)
- Qwen2.5-0.5B scores lowest in Logical Error (5.36)
3. **Outliers**:
- Claude-3-haiku-20240307: Strong across multiple categories (60.05-66.96)
- Llama-3.2-3B: Weak in Erroneous Assumption (25.33) and Logical Error (27.32)
### Interpretation
The data reveals a clear hierarchy in model capabilities:
1. **Scientific Misconception** is the strongest category across all models, suggesting better handling of factual reasoning tasks.
2. **Logical Error** represents the weakest area (avg 40.58), indicating challenges with deductive reasoning.
3. Larger models (e.g., Llama-3.1-70B) generally outperform smaller variants, though exceptions exist (e.g., Qwen2.5-0.5B's poor Logical Error score).
4. The "Others" category shows mixed performance, with some models (e.g., Claude-3-haiku) demonstrating relative strength.
This pattern suggests AI systems may prioritize factual recall (Scientific Misconception) over abstract reasoning (Logical Error), with performance varying significantly by model architecture and training data.