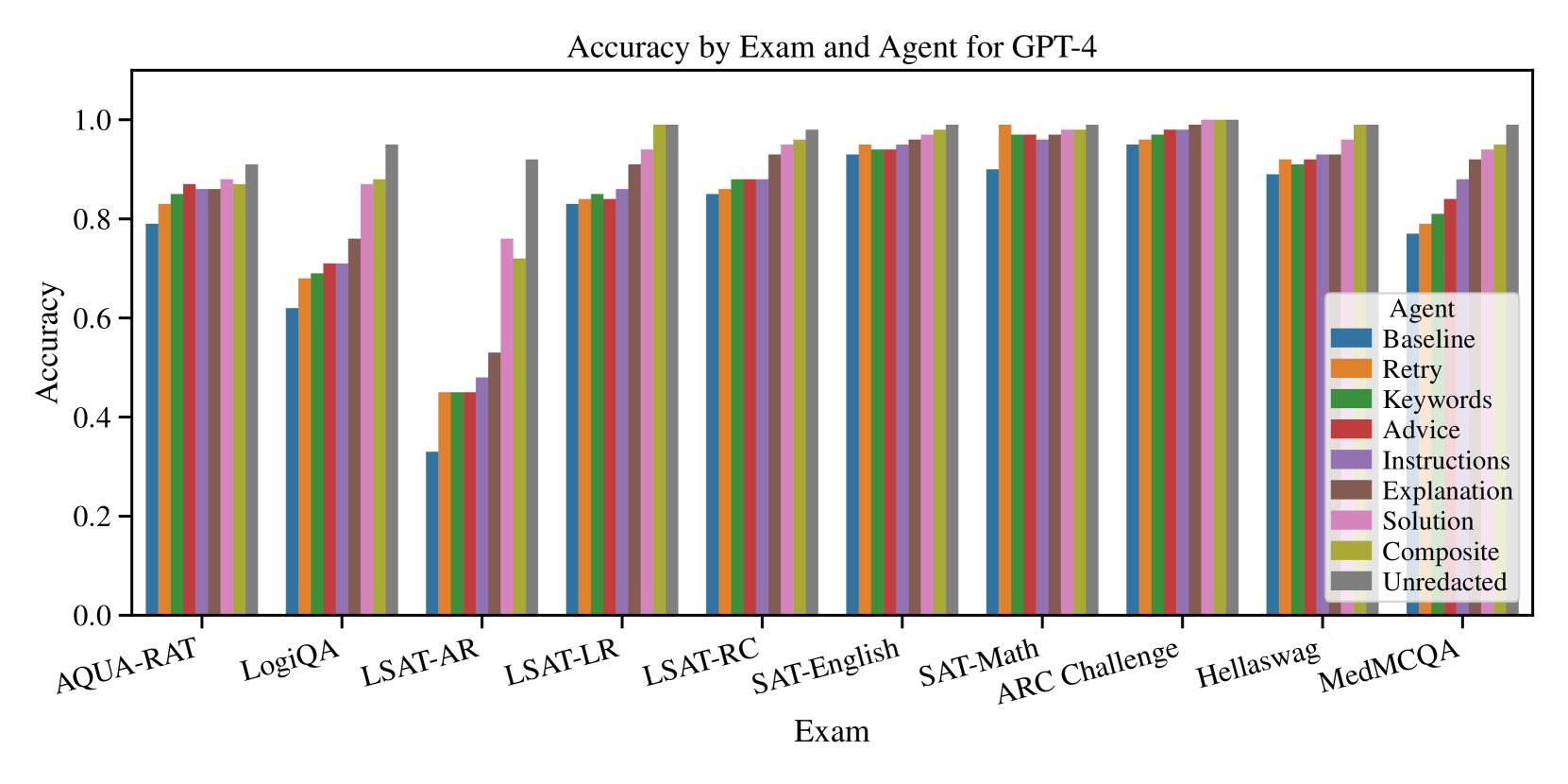
## Bar Chart: Accuracy by Exam and Agent for GPT-4
### Overview
The chart compares the accuracy of different agents (Baseline, Retry, Keywords, Advice, Instructions, Explanation, Solution, Composite, Unredacted) across 10 exams (AQUA-RAT, LogiQA, LSAT-AR, LSAT-LR, LSAT-RC, SAT-English, SAT-Math, ARC Challenge, Hellaswag, MedMCQA). Accuracy values range from 0.0 to 1.0 on the y-axis, with exams listed on the x-axis.
### Components/Axes
- **X-axis (Exams)**: AQUA-RAT, LogiQA, LSAT-AR, LSAT-LR, LSAT-RC, SAT-English, SAT-Math, ARC Challenge, Hellaswag, MedMCQA.
- **Y-axis (Accuracy)**: 0.0 to 1.0 in increments of 0.2.
- **Legend (Agents)**:
- Baseline (blue)
- Retry (orange)
- Keywords (green)
- Advice (red)
- Instructions (purple)
- Explanation (brown)
- Solution (pink)
- Composite (yellow)
- Unredacted (gray)
### Detailed Analysis
- **AQUA-RAT**:
- Baseline (blue): ~0.80
- Retry (orange): ~0.83
- Keywords (green): ~0.85
- Advice (red): ~0.87
- Instructions (purple): ~0.86
- Explanation (brown): ~0.88
- Solution (pink): ~0.89
- Composite (yellow): ~0.87
- Unredacted (gray): ~0.92
- **LogiQA**:
- Baseline (blue): ~0.62
- Retry (orange): ~0.68
- Keywords (green): ~0.69
- Advice (red): ~0.71
- Instructions (purple): ~0.70
- Explanation (brown): ~0.76
- Solution (pink): ~0.87
- Composite (yellow): ~0.88
- Unredacted (gray): ~0.95
- **LSAT-AR**:
- Baseline (blue): ~0.35
- Retry (orange): ~0.45
- Keywords (green): ~0.45
- Advice (red): ~0.45
- Instructions (purple): ~0.48
- Explanation (brown): ~0.52
- Solution (pink): ~0.75
- Composite (yellow): ~0.72
- Unredacted (gray): ~0.92
- **LSAT-LR**:
- Baseline (blue): ~0.83
- Retry (orange): ~0.84
- Keywords (green): ~0.85
- Advice (red): ~0.86
- Instructions (purple): ~0.87
- Explanation (brown): ~0.90
- Solution (pink): ~0.92
- Composite (yellow): ~0.99
- Unredacted (gray): ~0.99
- **LSAT-RC**:
- Baseline (blue): ~0.85
- Retry (orange): ~0.87
- Keywords (green): ~0.88
- Advice (red): ~0.89
- Instructions (purple): ~0.90
- Explanation (brown): ~0.93
- Solution (pink): ~0.95
- Composite (yellow): ~0.96
- Unredacted (gray): ~0.98
- **SAT-English**:
- Baseline (blue): ~0.91
- Retry (orange): ~0.92
- Keywords (green): ~0.92
- Advice (red): ~0.91
- Instructions (purple): ~0.93
- Explanation (brown): ~0.94
- Solution (pink): ~0.96
- Composite (yellow): ~0.97
- Unredacted (gray): ~0.99
- **SAT-Math**:
- Baseline (blue): ~0.88
- Retry (orange): ~0.99
- Keywords (green): ~0.97
- Advice (red): ~0.97
- Instructions (purple): ~0.96
- Explanation (brown): ~0.97
- Solution (pink): ~0.98
- Composite (yellow): ~0.99
- Unredacted (gray): ~0.99
- **ARC Challenge**:
- Baseline (blue): ~0.94
- Retry (orange): ~0.95
- Keywords (green): ~0.96
- Advice (red): ~0.97
- Instructions (purple): ~0.97
- Explanation (brown): ~0.98
- Solution (pink): ~0.99
- Composite (yellow): ~0.98
- Unredacted (gray): ~0.99
- **Hellaswag**:
- Baseline (blue): ~0.90
- Retry (orange): ~0.92
- Keywords (green): ~0.91
- Advice (red): ~0.93
- Instructions (purple): ~0.94
- Explanation (brown): ~0.95
- Solution (pink): ~0.97
- Composite (yellow): ~0.98
- Unredacted (gray): ~0.99
- **MedMCQA**:
- Baseline (blue): ~0.78
- Retry (orange): ~0.80
- Keywords (green): ~0.82
- Advice (red): ~0.85
- Instructions (purple): ~0.87
- Explanation (brown): ~0.90
- Solution (pink): ~0.92
- Composite (yellow): ~0.94
- Unredacted (gray): ~0.97
### Key Observations
1. **Unredacted (gray)** and **Composite (yellow)** agents consistently achieve the highest accuracy across most exams, often reaching ~0.95–0.99.
2. **Baseline (blue)** performs poorly in **LSAT-AR** (~0.35) but improves to ~0.94 in **ARC Challenge**.
3. **Retry (orange)** and **Keywords (green)** show moderate performance, with **Retry** outperforming **Keywords** in **LogiQA** (~0.68 vs. ~0.69).
4. **Instructions (purple)** and **Explanation (brown)** demonstrate strong performance in **LSAT-AR** (~0.48 and ~0.52, respectively), though still below top agents.
5. **SAT-Math** and **ARC Challenge** have the highest overall accuracy, with most agents exceeding 0.95.
### Interpretation
The data suggests that **Unredacted** and **Composite** agents are the most robust, likely due to their ability to synthesize information or avoid redaction errors. **Baseline** struggles in **LSAT-AR**, indicating potential limitations in handling specific question types. **Retry** and **Keywords** perform variably, with **Retry** excelling in **LogiQA** but underperforming in **SAT-Math**. The **Solution** and **Explanation** agents show promise in reasoning-heavy exams like **LSAT-RC** and **SAT-Math**, suggesting their effectiveness in structured problem-solving. The **Hellaswag** and **MedMCQA** exams highlight the importance of contextual understanding, as top agents achieve near-perfect accuracy here. Overall, agent design significantly impacts performance, with specialized agents outperforming generic ones in domain-specific tasks.