TECHNICAL ASSET FINGERPRINT
63d1dc2b0824a5cc5ac4ff77
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
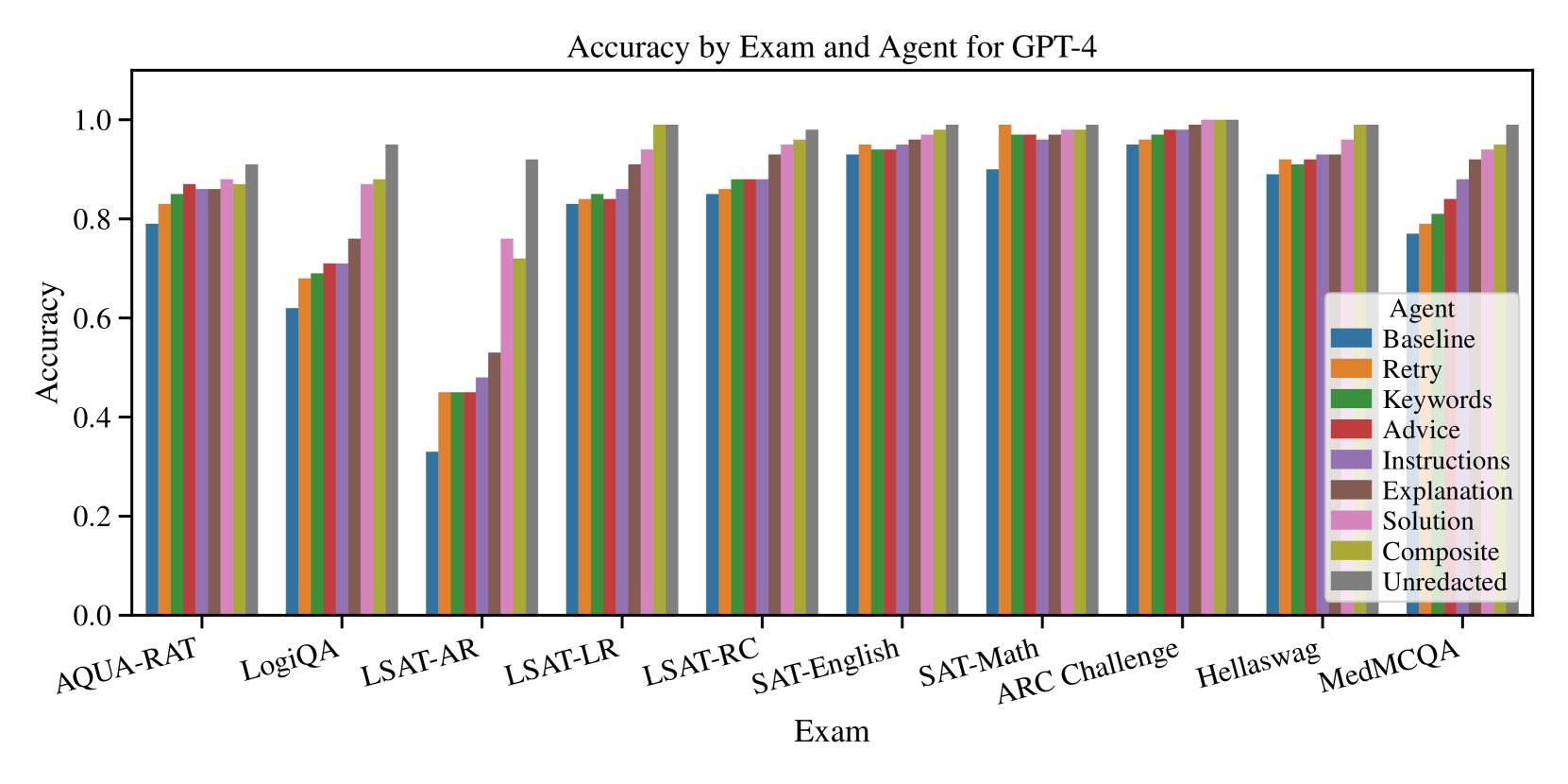
## Grouped Bar Chart: Accuracy by Exam and Agent for GPT-4
### Overview
This is a grouped bar chart comparing the accuracy of GPT-4 across ten different exams or benchmarks, using nine different prompting "Agent" strategies. The chart visualizes how various prompting techniques affect performance on different types of tasks.
### Components/Axes
* **Chart Title:** "Accuracy by Exam and Agent for GPT-4"
* **Y-Axis:** Labeled "Accuracy". The scale runs from 0.0 to 1.0, with major tick marks at 0.0, 0.2, 0.4, 0.6, 0.8, and 1.0.
* **X-Axis:** Labeled "Exam". It lists ten distinct exam/benchmark categories.
* **Legend:** Located in the bottom-right quadrant of the chart area. It is titled "Agent" and defines the color coding for nine different prompting strategies.
* **Baseline:** Blue
* **Retry:** Orange
* **Keywords:** Green
* **Advice:** Red
* **Instructions:** Purple
* **Explanation:** Brown
* **Solution:** Pink
* **Composite:** Olive/Yellow-Green
* **Unredacted:** Gray
### Detailed Analysis
Data is presented as clusters of nine bars (one per Agent) for each Exam. Values are approximate based on visual alignment with the y-axis.
**1. AQUA-RAT**
* **Trend:** General upward trend from Baseline to Unredacted, with a slight dip for Instructions.
* **Approximate Values:** Baseline ~0.79, Retry ~0.83, Keywords ~0.85, Advice ~0.87, Instructions ~0.86, Explanation ~0.86, Solution ~0.88, Composite ~0.87, Unredacted ~0.91.
**2. LogiQA**
* **Trend:** Steady, consistent increase from Baseline to Unredacted.
* **Approximate Values:** Baseline ~0.62, Retry ~0.68, Keywords ~0.69, Advice ~0.71, Instructions ~0.71, Explanation ~0.76, Solution ~0.87, Composite ~0.88, Unredacted ~0.95.
**3. LSAT-AR**
* **Trend:** Significant overall increase. Baseline is notably low. A large jump occurs between Instructions and Solution.
* **Approximate Values:** Baseline ~0.33, Retry ~0.45, Keywords ~0.45, Advice ~0.45, Instructions ~0.48, Explanation ~0.53, Solution ~0.76, Composite ~0.72, Unredacted ~0.92.
**4. LSAT-LR**
* **Trend:** Gradual, consistent increase across all agents.
* **Approximate Values:** Baseline ~0.83, Retry ~0.84, Keywords ~0.85, Advice ~0.85, Instructions ~0.86, Explanation ~0.91, Solution ~0.94, Composite ~0.99, Unredacted ~0.99.
**5. LSAT-RC**
* **Trend:** Steady increase, with all agents performing above 0.8.
* **Approximate Values:** Baseline ~0.85, Retry ~0.86, Keywords ~0.88, Advice ~0.88, Instructions ~0.88, Explanation ~0.93, Solution ~0.96, Composite ~0.97, Unredacted ~0.98.
**6. SAT-English**
* **Trend:** High baseline performance with a slight, steady increase. All values are above 0.9.
* **Approximate Values:** Baseline ~0.93, Retry ~0.95, Keywords ~0.94, Advice ~0.94, Instructions ~0.95, Explanation ~0.97, Solution ~0.98, Composite ~0.99, Unredacted ~0.99.
**7. SAT-Math**
* **Trend:** Very high performance across the board. A slight dip for Instructions relative to adjacent bars.
* **Approximate Values:** Baseline ~0.90, Retry ~0.99, Keywords ~0.97, Advice ~0.97, Instructions ~0.96, Explanation ~0.98, Solution ~0.99, Composite ~0.99, Unredacted ~0.99.
**8. ARC Challenge**
* **Trend:** Extremely high and consistent performance. All bars are near or at 1.0.
* **Approximate Values:** Baseline ~0.95, Retry ~0.96, Keywords ~0.97, Advice ~0.98, Instructions ~0.98, Explanation ~0.99, Solution ~1.00, Composite ~1.00, Unredacted ~1.00.
**9. Hellaswag**
* **Trend:** High baseline with a gradual increase. Composite and Unredacted are near perfect.
* **Approximate Values:** Baseline ~0.89, Retry ~0.92, Keywords ~0.91, Advice ~0.92, Instructions ~0.93, Explanation ~0.93, Solution ~0.96, Composite ~0.99, Unredacted ~0.99.
**10. MedMCQA**
* **Trend:** Clear, strong upward trend from Baseline to Unredacted.
* **Approximate Values:** Baseline ~0.77, Retry ~0.79, Keywords ~0.80, Advice ~0.84, Instructions ~0.88, Explanation ~0.91, Solution ~0.94, Composite ~0.95, Unredacted ~0.99.
### Key Observations
1. **Agent Performance Hierarchy:** Across nearly all exams, the "Unredacted" agent (gray bar) achieves the highest or tied-for-highest accuracy. "Composite" (olive) is consistently the second-best. "Baseline" (blue) is almost always the lowest.
2. **Exam Difficulty Spectrum:** The exams show a wide range of baseline difficulty for GPT-4. LSAT-AR appears the hardest (baseline ~0.33), while ARC Challenge appears the easiest (baseline ~0.95).
3. **Impact of Prompting:** The improvement from "Baseline" to "Unredacted" is dramatic on harder exams (e.g., LSAT-AR: +~0.59) but marginal on easier ones (e.g., ARC Challenge: +~0.05).
4. **Non-Linear Gains:** Performance does not always improve linearly with each agent. Significant jumps often occur at "Explanation", "Solution", or "Composite" stages, suggesting these prompting strategies are particularly effective.
5. **SAT-Math Anomaly:** The "Retry" agent (orange) shows a very high accuracy (~0.99) on SAT-Math, nearly matching the top performers, which is unusual compared to its performance on other exams.
### Interpretation
This chart demonstrates the significant impact of advanced prompting strategies on GPT-4's reasoning and knowledge-based performance. The data suggests that simply using the base model ("Baseline") leaves substantial capability untapped, especially on complex, structured reasoning tasks like the LSAT Analytical Reasoning section.
The consistent superiority of "Unredacted" and "Composite" agents implies that providing the model with more context, explicit instructions, and worked examples ("Solution") synergistically improves its accuracy. The diminishing returns on easier benchmarks (like ARC Challenge) indicate a performance ceiling where prompting strategies matter less because the task is well within the model's base capabilities.
The outlier on SAT-Math, where "Retry" performs exceptionally well, might indicate that for certain types of mathematical problems, a simple retry mechanism is highly effective, possibly by allowing the model to catch and correct computational or simple logical errors on a second attempt.
Overall, the chart is a strong argument for the importance of prompt engineering and agentic workflows in maximizing the utility of large language models, transforming them from capable base models into highly reliable problem-solving tools across diverse domains.
DECODING INTELLIGENCE...