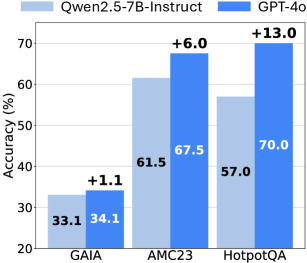
## Bar Chart: Model Accuracy Comparison Across Datasets
### Overview
The chart compares the accuracy of two AI models, **Qwen2.5-7B-Instruct** (light blue) and **GPT-4o** (dark blue), across three question-answering datasets: **GAIA**, **AMC23**, and **HotpotQA**. Accuracy is measured in percentage (%), with incremental improvements highlighted as deltas (+X.X) above each bar.
### Components/Axes
- **X-axis**: Datasets (GAIA, AMC23, HotpotQA), evenly spaced.
- **Y-axis**: Accuracy (%) ranging from 20% to 70%, with gridlines at 10% intervals.
- **Legend**: Located at the top-left, associating colors with models:
- Light blue: Qwen2.5-7B-Instruct
- Dark blue: GPT-4o
- **Bar Structure**: Each dataset has two adjacent bars (Qwen2.5-7B-Instruct on the left, GPT-4o on the right), with values and deltas labeled.
### Detailed Analysis
1. **GAIA**:
- Qwen2.5-7B-Instruct: 33.1% accuracy.
- GPT-4o: 34.1% accuracy (+1.1% improvement).
2. **AMC23**:
- Qwen2.5-7B-Instruct: 61.5% accuracy.
- GPT-4o: 67.5% accuracy (+6.0% improvement).
3. **HotpotQA**:
- Qwen2.5-7B-Instruct: 57.0% accuracy.
- GPT-4o: 70.0% accuracy (+13.0% improvement).
### Key Observations
- **GPT-4o consistently outperforms Qwen2.5-7B-Instruct** across all datasets.
- The largest improvement (+13.0%) occurs in **HotpotQA**, where GPT-4o achieves a 70.0% accuracy compared to Qwen2.5-7B-Instruct's 57.0%.
- The smallest improvement (+1.1%) is in **GAIA**, where both models perform relatively poorly (33.1% vs. 34.1%).
### Interpretation
The data demonstrates that **GPT-4o significantly surpasses Qwen2.5-7B-Instruct** in accuracy, particularly in complex tasks like HotpotQA. The incremental improvements suggest that GPT-4o's architecture or training data may be better suited for these question-answering benchmarks. The minimal gain in GAIA implies that both models struggle with this dataset, highlighting potential limitations in handling specific question types or knowledge domains. This comparison underscores the importance of model selection based on task complexity and dataset characteristics.