## Bar Chart: Model Accuracy Comparison
### Overview
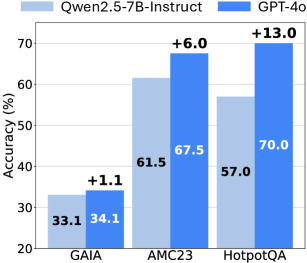
The image is a bar chart comparing the accuracy of two language models, Qwen2.5-7B-Instruct and GPT-4o, on three different datasets: GAIA, AMC23, and HotpotQA. The chart displays the accuracy percentage for each model on each dataset, along with the difference in accuracy between the two models.
### Components/Axes
* **Title:** (Inferred) Model Accuracy Comparison
* **X-axis:** Datasets (GAIA, AMC23, HotpotQA)
* **Y-axis:** Accuracy (%) with a scale from 20 to 70 in increments of 10.
* **Legend:** Located at the top of the chart.
* Light Blue: Qwen2.5-7B-Instruct
* Dark Blue: GPT-4o
* **Annotations:** "+X.X" above each pair of bars, indicating the difference in accuracy between GPT-4o and Qwen2.5-7B-Instruct.
### Detailed Analysis
* **GAIA Dataset:**
* Qwen2.5-7B-Instruct: Accuracy of 33.1%
* GPT-4o: Accuracy of 34.1%
* Difference: +1.1%
* Trend: GPT-4o performs slightly better than Qwen2.5-7B-Instruct.
* **AMC23 Dataset:**
* Qwen2.5-7B-Instruct: Accuracy of 61.5%
* GPT-4o: Accuracy of 67.5%
* Difference: +6.0%
* Trend: GPT-4o performs better than Qwen2.5-7B-Instruct.
* **HotpotQA Dataset:**
* Qwen2.5-7B-Instruct: Accuracy of 57.0%
* GPT-4o: Accuracy of 70.0%
* Difference: +13.0%
* Trend: GPT-4o performs significantly better than Qwen2.5-7B-Instruct.
### Key Observations
* GPT-4o consistently outperforms Qwen2.5-7B-Instruct across all three datasets.
* The largest performance difference between the two models is observed on the HotpotQA dataset.
* The smallest performance difference is observed on the GAIA dataset.
### Interpretation
The bar chart provides a comparative analysis of the accuracy of two language models, Qwen2.5-7B-Instruct and GPT-4o, on three different datasets. The data suggests that GPT-4o generally achieves higher accuracy than Qwen2.5-7B-Instruct across these datasets. The magnitude of the performance difference varies depending on the dataset, with HotpotQA showing the most significant improvement for GPT-4o. This could indicate that GPT-4o is better suited for tasks involving complex reasoning or information retrieval, as HotpotQA is known for its multi-hop question answering challenges. The GAIA dataset shows a minimal difference, suggesting that both models perform similarly on tasks represented by this dataset. Overall, the chart highlights the relative strengths and weaknesses of the two models across different types of tasks.