\n
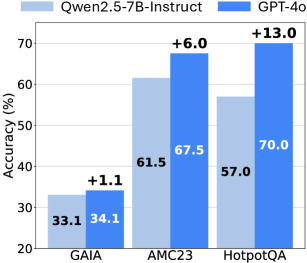
## Bar Chart: Accuracy Comparison of Qwen2.5-7B-Instruct and GPT-4o
### Overview
This bar chart compares the accuracy of two language models, Qwen2.5-7B-Instruct and GPT-4o, across three different datasets: GAIA, AMC23, and HotpotQA. Accuracy is measured in percentage points. Each dataset has two bars representing the accuracy of each model. The difference in accuracy between the two models is indicated above each pair of bars.
### Components/Axes
* **X-axis:** Datasets - GAIA, AMC23, HotpotQA
* **Y-axis:** Accuracy (%) - Scale ranges from 20% to 70% with increments of 10%.
* **Legend:**
* Light Blue: Qwen2.5-7B-Instruct
* Dark Blue: GPT-4o
* **Labels:** Each bar is labeled with its corresponding accuracy value. Difference labels are positioned above the bar pairs.
### Detailed Analysis
**GAIA:**
* Qwen2.5-7B-Instruct: The light blue bar reaches approximately 33.1% accuracy.
* GPT-4o: The dark blue bar reaches approximately 34.1% accuracy.
* Difference: +1.1% (GPT-4o is 1.1% more accurate than Qwen2.5-7B-Instruct).
**AMC23:**
* Qwen2.5-7B-Instruct: The light blue bar reaches approximately 61.5% accuracy.
* GPT-4o: The dark blue bar reaches approximately 67.5% accuracy.
* Difference: +6.0% (GPT-4o is 6.0% more accurate than Qwen2.5-7B-Instruct).
**HotpotQA:**
* Qwen2.5-7B-Instruct: The light blue bar reaches approximately 57.0% accuracy.
* GPT-4o: The dark blue bar reaches approximately 70.0% accuracy.
* Difference: +13.0% (GPT-4o is 13.0% more accurate than Qwen2.5-7B-Instruct).
### Key Observations
* GPT-4o consistently outperforms Qwen2.5-7B-Instruct across all three datasets.
* The difference in accuracy is most significant on the HotpotQA dataset (+13.0%), indicating GPT-4o has a substantial advantage in this domain.
* The smallest difference in accuracy is observed on the GAIA dataset (+1.1%), suggesting both models perform similarly on this dataset.
### Interpretation
The data demonstrates that GPT-4o achieves higher accuracy than Qwen2.5-7B-Instruct on all three evaluated datasets. This suggests that GPT-4o is a more capable model overall, particularly when dealing with the types of questions and reasoning required by the HotpotQA dataset. The relatively small difference on GAIA might indicate that the task is simpler or that both models have been trained similarly on that type of data. The consistent positive difference for GPT-4o suggests a general advantage in its architecture, training data, or optimization process. The chart provides a quantitative comparison of the performance of these two models, which is valuable for selecting the appropriate model for a given task. The magnitude of the differences in accuracy could influence the choice of model based on the required level of performance.