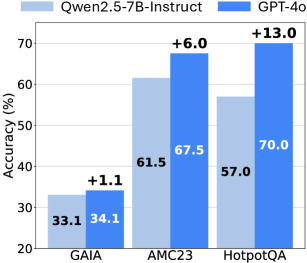
## Bar Chart: Model Accuracy Comparison on Three Datasets
### Overview
The image is a grouped bar chart comparing the accuracy percentages of two large language models—Qwen2.5-7B-Instruct and GPT-4o—across three distinct evaluation datasets: GAIA, AMC23, and HotpotQA. The chart visually highlights the performance gap between the two models on each task.
### Components/Axes
* **Chart Title:** None visible.
* **Y-Axis:** Labeled **"Accuracy (%)"**. The scale runs from 20 to 70, with major tick marks at 20, 30, 40, 50, 60, and 70.
* **X-Axis:** Lists three categorical datasets: **GAIA**, **AMC23**, and **HotpotQA**.
* **Legend:** Positioned at the top of the chart.
* Light blue square: **Qwen2.5-7B-Instruct**
* Dark blue square: **GPT-4o**
* **Data Series:** Two bars per dataset category, colored according to the legend.
* **Data Labels:** Numerical accuracy values are printed directly on or above each bar. The performance difference (GPT-4o minus Qwen2.5-7B-Instruct) is annotated above each pair of bars with a "+" sign.
### Detailed Analysis
**1. GAIA Dataset (Leftmost Group):**
* **Qwen2.5-7B-Instruct (Light Blue Bar):** Accuracy = **33.1%**. The bar extends from the baseline to just above the 30% mark.
* **GPT-4o (Dark Blue Bar):** Accuracy = **34.1%**. The bar is slightly taller than the Qwen bar.
* **Difference:** Annotated as **+1.1** above the bars, confirming GPT-4o's slight lead.
**2. AMC23 Dataset (Center Group):**
* **Qwen2.5-7B-Instruct (Light Blue Bar):** Accuracy = **61.5%**. The bar extends past the 60% line.
* **GPT-4o (Dark Blue Bar):** Accuracy = **67.5%**. The bar is noticeably taller, approaching the 70% line.
* **Difference:** Annotated as **+6.0** above the bars.
**3. HotpotQA Dataset (Rightmost Group):**
* **Qwen2.5-7B-Instruct (Light Blue Bar):** Accuracy = **57.0%**. The bar is between the 50% and 60% lines.
* **GPT-4o (Dark Blue Bar):** Accuracy = **70.0%**. The bar reaches the top of the y-axis scale at 70%.
* **Difference:** Annotated as **+13.0** above the bars, representing the largest performance gap.
**Trend Verification:**
* **Qwen2.5-7B-Instruct Trend:** Accuracy increases from GAIA (33.1%) to AMC23 (61.5%), then decreases for HotpotQA (57.0%). The line connecting the tops of its bars would rise sharply and then dip.
* **GPT-4o Trend:** Accuracy shows a consistent upward trend across the three datasets: GAIA (34.1%) < AMC23 (67.5%) < HotpotQA (70.0%). The line connecting its bar tops slopes upward from left to right.
### Key Observations
1. **Consistent Superiority:** GPT-4o achieves higher accuracy than Qwen2.5-7B-Instruct on all three presented datasets.
2. **Variable Performance Gap:** The margin of superiority is not constant. It is minimal on GAIA (+1.1%), moderate on AMC23 (+6.0%), and substantial on HotpotQA (+13.0%).
3. **Dataset Difficulty:** The absolute accuracy levels suggest varying task difficulty. GAIA appears to be the most challenging for both models (scores in the 30s), while AMC23 and HotpotQA yield higher scores (50s-70s).
4. **Model Behavior Divergence:** The models' performance trajectories differ. GPT-4o improves steadily, while Qwen2.5-7B-Instruct peaks on AMC23 and then regresses on HotpotQA.
### Interpretation
This chart demonstrates a comparative evaluation of two AI models on benchmarks likely testing different capabilities (e.g., GAIA for complex reasoning, AMC23 for math, HotpotQA for multi-hop question answering). The data suggests that while both models have foundational capabilities, **GPT-4o exhibits more robust and scalable performance**, particularly on the HotpotQA task, where its advantage is most pronounced.
The widening gap could indicate that GPT-4o handles the specific challenges of HotpotQA (which often requires synthesizing information from multiple sources) more effectively. Conversely, the similar scores on GAIA might imply a common performance ceiling or a task type where both models' capabilities are equally matched at this scale. The dip in Qwen's performance on HotpotQA relative to AMC23 is an anomaly worth investigating—it may point to a specific weakness in that model's architecture or training for that task category. Overall, the chart is a clear visual argument for GPT-4o's superior accuracy across this selection of benchmarks.