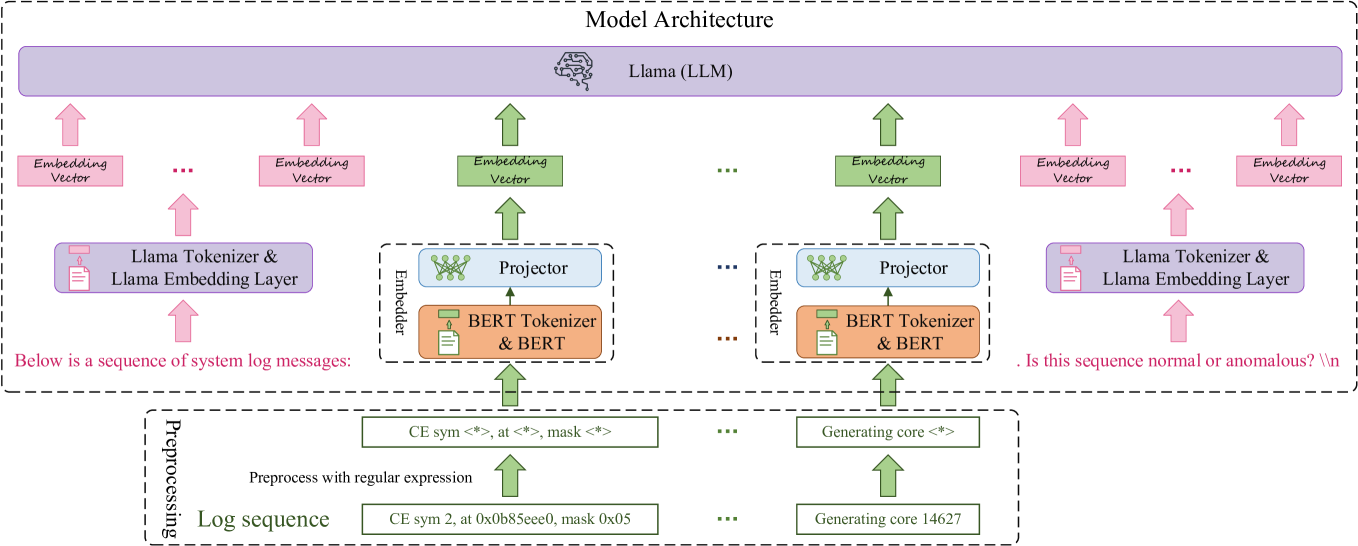
# Model Architecture Technical Document
## Overview
The diagram illustrates a hybrid model architecture combining **Llama (LLM)** with **BERT** components for sequence processing and anomaly detection. The architecture is divided into three primary sections: **Preprocessing**, **Model Architecture**, and **Output Question**.
---
## 1. Model Architecture Components
### 1.1 Llama (LLM) Layer
- **Color**: Purple rectangle spanning the entire width of the diagram.
- **Function**: Receives embedding vectors from lower layers.
- **Connections**:
- Receives **Embedding Vectors** from both left and right branches (pink and green arrows).
### 1.2 Embedding Vectors
- **Left Branch**:
- **Pink Embedding Vectors**: Generated by "Llama Tokenizer & Llama Embedding Layer".
- **Green Embedding Vectors**: Generated by "Projector" (connected to BERT components).
- **Right Branch**:
- **Pink Embedding Vectors**: Generated by "Llama Tokenizer & Llama Embedding Layer".
- **Green Embedding Vectors**: Generated by "Projector" (connected to BERT components).
### 1.3 BERT Integration
- **Left Branch**:
- **BERT Tokenizer & BERT**: Connected to a "Projector" (blue dashed box).
- **Projector**: Maps BERT embeddings to Llama-compatible vectors.
- **Right Branch**:
- Identical structure to the left branch (mirrored).
### 1.4 Preprocessing Section
- **Input**: Log sequences processed via regular expressions.
- **Examples**:
- `CE sym <*>, at <*>, mask <*>`
- `Generating core <*>`
- **Output**: Structured log sequences (e.g., `CE sym 2, at 0x0b85eee0, mask 0x05`).
---
## 2. Data Flow
1. **Preprocessing**:
- Raw log sequences are preprocessed using regex.
- Outputs structured sequences (e.g., `Generating core 14627`).
2. **Embedding**:
- Sequences are tokenized and embedded via:
- **Llama Tokenizer & Embedding Layer** (pink path).
- **BERT Tokenizer & BERT** (orange path, then projected via "Projector").
3. **Model Inference**:
- Embedding vectors from both paths feed into the **Llama (LLM)**.
4. **Output**:
- Final question: `"Is this sequence normal or anomalous? \\n"`.
---
## 3. Color Coding & Labels
| Color | Component | Legend Reference |
|-------------|------------------------------------|------------------|
| Pink | Llama Tokenizer & Embedding Layer | Top-left arrow |
| Green | Projector | Middle arrows |
| Purple | Llama (LLM) Layer | Top rectangle |
| Orange | BERT Tokenizer & BERT | Middle boxes |
---
## 4. Spatial Grounding
- **Top Section**: Llama (LLM) layer spans the entire width.
- **Middle Section**:
- Left and right branches are symmetric, each containing:
- Preprocessing → Embedding → Projector → BERT → Llama.
- **Bottom Section**: Preprocessing inputs and output question.
---
## 5. Key Trends & Observations
- **Dual Pathway Design**: Separate processing streams for Llama-native and BERT-derived embeddings.
- **Hybrid Embedding**: Combines Llama and BERT embeddings via projectors for Llama input.
- **Anomaly Detection Focus**: Final question implies classification of sequence normality.
---
## 6. Missing Elements
- No numerical data, charts, or tables present.
- No explicit axis titles or legends beyond component labels.
---
## 7. Technical Notes
- **Tokenizer Roles**:
- **Llama Tokenizer**: Converts text to Llama-specific tokens.
- **BERT Tokenizer**: Converts text to BERT-specific tokens (e.g., `mask`, ``).
- **Projector Function**: Bridges BERT and Llama embedding spaces.
---
This architecture suggests a system for analyzing system log messages (e.g., `CE sym 2, at 0x0b85eee0, mask 0x05`) to determine normality using a hybrid Llama-BERT model.