# Technical Document Extraction: Model Architecture for Log Analysis
## 1. Overview
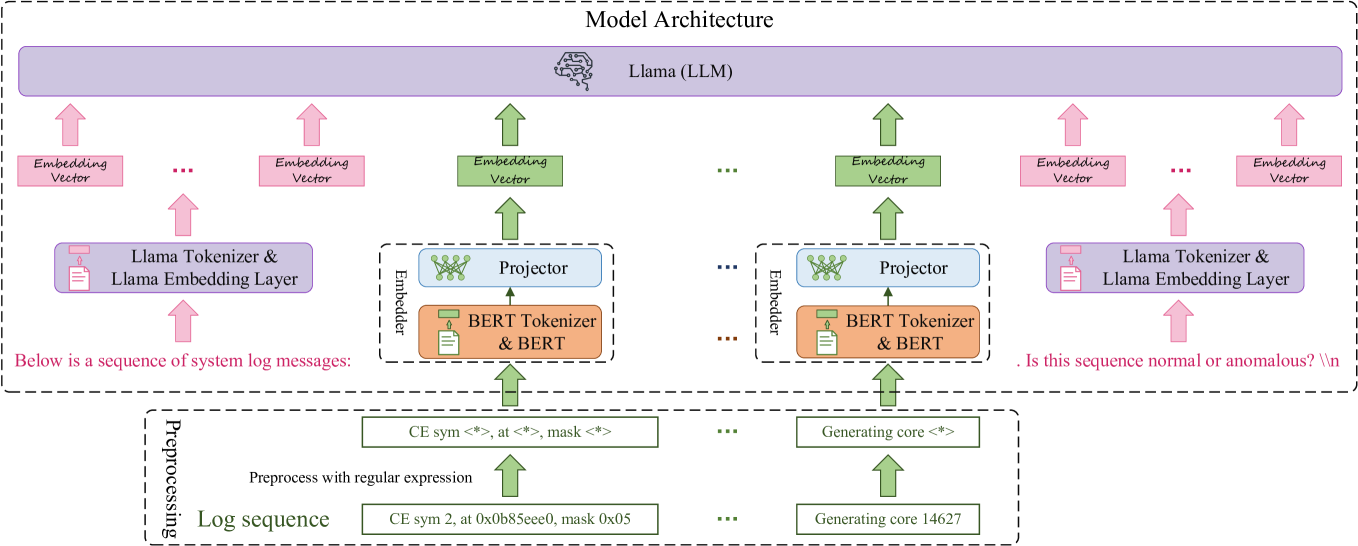
The image illustrates a technical architecture for a Large Language Model (LLM) based system designed to analyze system log sequences for anomaly detection. The architecture integrates a pre-trained LLM (Llama) with specialized embedders (BERT) to process both natural language prompts and structured log data.
---
## 2. Component Segmentation
### Region 1: Header / Core Model
* **Main Container:** Labeled "Model Architecture" (dashed boundary).
* **Central Processor:** A large purple horizontal block labeled **"Llama (LLM)"** with a brain icon. This serves as the primary reasoning engine.
### Region 2: Input Processing (Prompting)
This region handles the natural language context surrounding the log data.
* **Text Prompts:**
* **Prefix (Left):** "Below is a sequence of logs..."
* **Suffix (Right):** "Is this sequence anomalous?"
* **Embedding Layer:** Both prefix and suffix are processed through a **BERT Embedder** (represented by blue blocks) to convert text into vector representations.
### Region 3: Log Sequence Processing
This region handles the structured log data.
* **Log Sequence:** A series of discrete log events (e.g., Log 1, Log 2, ..., Log N).
* **Log Embedder:** Each log entry is passed through a dedicated **BERT Embedder**.
* **Vector Representation:** The output is a sequence of vectors ($v_1, v_2, ..., v_n$).
### Region 4: Integration and Output
* **Concatenation:** The embedded Prefix, Log Vectors, and Suffix are concatenated into a single input sequence for the Llama model.
* **Output:** The model generates a classification or response based on the integrated context.