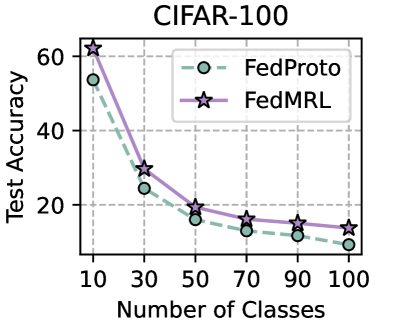
## Line Graph: CIFAR-100 Test Accuracy vs. Number of Classes
### Overview
The chart compares the test accuracy of two federated learning methods, **FedProto** and **FedMRL**, across varying numbers of classes (10 to 100) on the CIFAR-100 dataset. Both methods show declining accuracy as the number of classes increases, with FedMRL consistently outperforming FedProto.
### Components/Axes
- **Title**: "CIFAR-100" (top-center).
- **Y-Axis**: "Test Accuracy" (percentage, 0–60, linear scale).
- **X-Axis**: "Number of Classes" (10–100, linear scale).
- **Legend**: Top-right corner, with:
- **FedProto**: Dashed green line with hollow circles.
- **FedMRL**: Solid purple line with star markers.
### Detailed Analysis
#### FedProto (Green Dashed Line)
- **10 classes**: ~55% accuracy.
- **30 classes**: ~25% accuracy.
- **50 classes**: ~15% accuracy.
- **70 classes**: ~12% accuracy.
- **90 classes**: ~10% accuracy.
- **100 classes**: ~8% accuracy.
#### FedMRL (Purple Solid Line)
- **10 classes**: ~60% accuracy.
- **30 classes**: ~30% accuracy.
- **50 classes**: ~20% accuracy.
- **70 classes**: ~15% accuracy.
- **90 classes**: ~13% accuracy.
- **100 classes**: ~12% accuracy.
### Key Observations
1. **Declining Trends**: Both methods exhibit a monotonic decline in accuracy as the number of classes increases.
2. **Performance Gap**: FedMRL maintains a ~10–15% accuracy advantage over FedProto across all class counts.
3. **Convergence**: The gap narrows slightly at 100 classes (FedMRL: 12% vs. FedProto: 8%), but FedMRL remains superior.
4. **Steepest Drop**: FedProto’s accuracy drops sharply from 55% to 25% between 10 and 30 classes, while FedMRL’s decline is more gradual.
### Interpretation
The data suggests that **FedMRL** is more robust to class imbalance or complexity in CIFAR-100 compared to **FedProto**. The steeper initial drop for FedProto implies it may rely heavily on class-specific features that become less discriminative as class diversity increases. FedMRL’s slower decline could indicate better generalization or more effective feature aggregation across classes. However, both methods struggle significantly beyond 50 classes, highlighting the challenge of scalability in federated learning for high-dimensional datasets like CIFAR-100. The convergence at 100 classes suggests that further improvements may require architectural innovations or hybrid approaches.