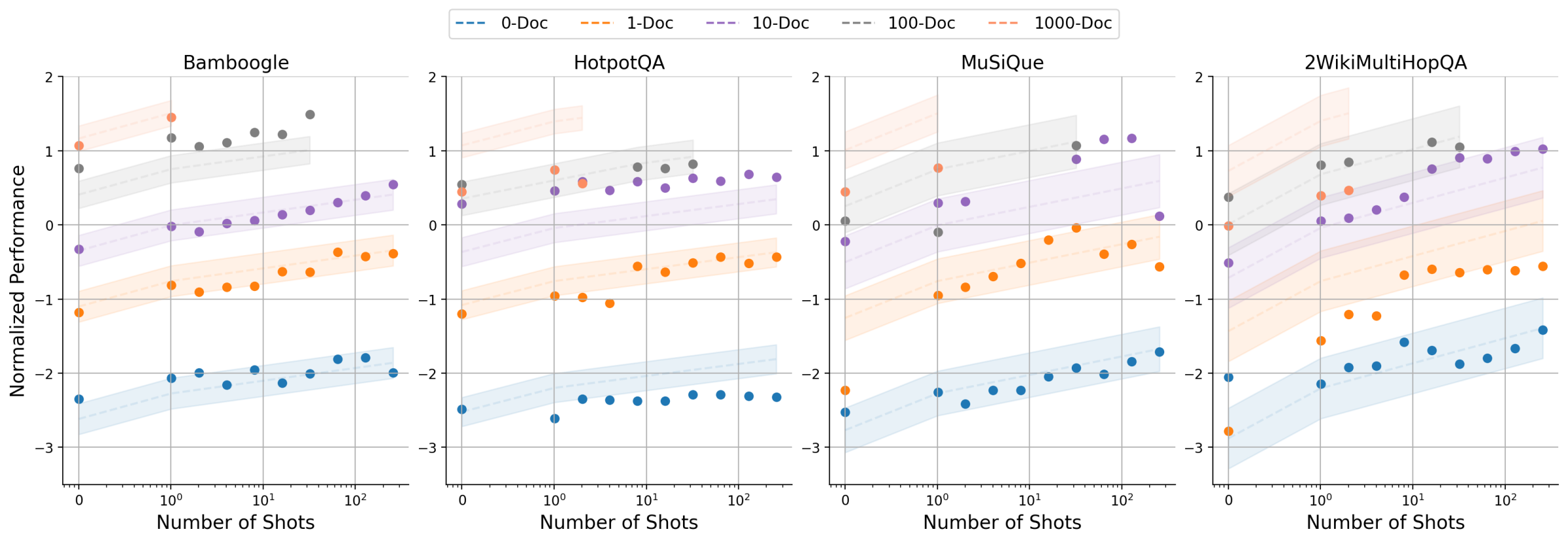
# Technical Data Extraction: Normalized Performance vs. Number of Shots
## 1. Document Overview
This image contains four side-by-side scatter plots with regression trend lines and confidence intervals. The charts evaluate the "Normalized Performance" of a system across four different datasets (Bamboogle, HotpotQA, MuSiQue, and 2WikiMultiHopQA) based on the "Number of Shots" provided.
## 2. Global Metadata and Legend
* **Header Legend [Top Center]:**
* `-- 0-Doc` (Blue dashed line/points)
* `-- 1-Doc` (Orange dashed line/points)
* `-- 10-Doc` (Purple dashed line/points)
* `-- 100-Doc` (Grey dashed line/points)
* `-- 1000-Doc` (Light Salmon/Pink dashed line/points)
* **Y-Axis (Common):** "Normalized Performance" (Scale: -3 to 2, increments of 1).
* **X-Axis (Common):** "Number of Shots" (Logarithmic scale: $0, 10^0, 10^1, 10^2$). Note: The '0' shot is plotted on the far left before the log scale break.
---
## 3. Component Analysis by Dataset
### A. Bamboogle
* **Trend Analysis:** All series show a positive correlation between the number of shots and performance.
* **Data Series Details:**
* **0-Doc (Blue):** Lowest performance. Starts at approx. -2.4 (0 shots), rises steadily to approx. -2.0 at 256 shots.
* **1-Doc (Orange):** Starts at approx. -1.2 (0 shots), rises to approx. -0.4 at 256 shots.
* **10-Doc (Purple):** Starts at approx. -0.3 (0 shots), rises to approx. 0.5 at 256 shots.
* **100-Doc (Grey):** Starts at approx. 0.8 (0 shots), rises to approx. 1.5 at 32 shots (data ends early).
* **1000-Doc (Salmon):** Highest performance. Starts at approx. 1.1 (0 shots), rises to approx. 1.5 at 1 shot (data ends early).
### B. HotpotQA
* **Trend Analysis:** Similar upward trajectory across all series, though the slope for 0-Doc is flatter than in Bamboogle.
* **Data Series Details:**
* **0-Doc (Blue):** Starts at approx. -2.5, ends at approx. -2.3.
* **1-Doc (Orange):** Starts at approx. -1.2, ends at approx. -0.4.
* **10-Doc (Purple):** Starts at approx. 0.3, ends at approx. 0.7.
* **100-Doc (Grey):** Starts at approx. 0.5, ends at approx. 0.8 (at 32 shots).
* **1000-Doc (Salmon):** Starts at approx. 0.4, peaks near 0.7 (at 2 shots).
### C. MuSiQue
* **Trend Analysis:** Steeper improvement curves compared to the first two datasets, particularly for the 10-Doc (Purple) series.
* **Data Series Details:**
* **0-Doc (Blue):** Starts at approx. -2.5, ends at approx. -1.7.
* **1-Doc (Orange):** Starts at approx. -2.2 (significant outlier/low start), rises sharply to approx. -0.6.
* **10-Doc (Purple):** Starts at approx. -0.2, rises significantly to approx. 1.2.
* **100-Doc (Grey):** Starts at approx. 0.1, reaches approx. 0.9 (at 32 shots).
* **1000-Doc (Salmon):** Starts at approx. 0.5, reaches approx. 0.8 (at 1 shot).
### D. 2WikiMultiHopQA
* **Trend Analysis:** Shows the widest variance at 0 shots. All series exhibit strong upward trends.
* **Data Series Details:**
* **0-Doc (Blue):** Starts at approx. -2.1, ends at approx. -1.4.
* **1-Doc (Orange):** Starts very low at approx. -2.8, rises sharply to approx. -0.6.
* **10-Doc (Purple):** Starts at approx. -0.5, rises to approx. 1.0.
* **100-Doc (Grey):** Starts at approx. 0.4, reaches approx. 1.1 (at 32 shots).
* **1000-Doc (Salmon):** Starts at approx. 0.0, reaches approx. 0.5 (at 2 shots).
---
## 4. Key Observations & Patterns
1. **Document Count Impact:** There is a clear vertical stratification. Increasing the number of documents (from 0-Doc to 1000-Doc) consistently shifts the performance baseline upward across all datasets.
2. **Shot Scaling:** Performance generally improves as the "Number of Shots" increases from 0 to 256. The improvement is most pronounced in the 1-Doc and 10-Doc series.
3. **Data Density:** The 0-Doc, 1-Doc, and 10-Doc series contain data points up to 256 shots. The 100-Doc series terminates at 32 shots, and the 1000-Doc series terminates at 1 or 2 shots, likely due to context window limitations.
4. **Consistency:** The relative ordering of the document counts (0 < 1 < 10 < 100 < 1000) is maintained across all four benchmarks, indicating a robust correlation between retrieved document volume and model performance.