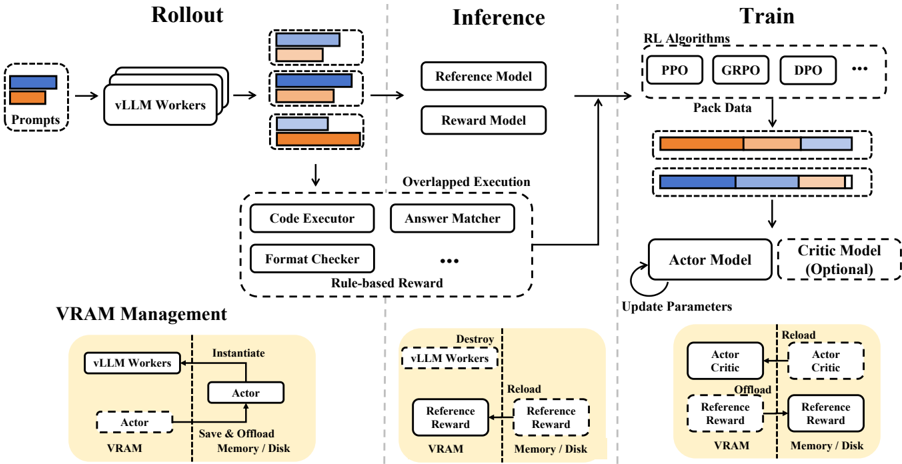
## System Diagram: Reinforcement Learning Workflow
### Overview
The image is a system diagram illustrating a reinforcement learning workflow, likely for training large language models (LLMs). It is divided into three main stages: Rollout, Inference, and Train, with a section on VRAM Management. The diagram shows the flow of data and processes between different components, including models, executors, and memory management.
### Components/Axes
* **Title:** Reinforcement Learning Workflow (implied)
* **Sections:**
* Rollout (top-left)
* Inference (top-center)
* Train (top-right)
* VRAM Management (bottom)
* **Nodes:**
* Prompts
* vLLM Workers
* Reference Model
* Reward Model
* Code Executor
* Answer Matcher
* Format Checker
* RL Algorithms (PPO, GRPO, DPO, ...)
* Actor Model
* Critic Model (Optional)
* Actor
* Reference Reward
* **Edges:** Arrows indicating the flow of data and control.
* **VRAM Management:** Shows instantiation, saving/offloading, destroying, and reloading of models between VRAM and Memory/Disk.
### Detailed Analysis
**1. Rollout Stage (Top-Left):**
* **Prompts:** A box labeled "Prompts" on the left. It contains two horizontal bars, one orange and one blue, representing data or information.
* **vLLM Workers:** "Prompts" feeds into a stack of three boxes labeled "vLLM Workers."
* **Output:** The output of "vLLM Workers" is a set of three boxes, each containing two horizontal bars (one orange, one blue), similar to the "Prompts" box. The relative lengths of the orange and blue bars vary slightly between the three output boxes.
**2. Inference Stage (Top-Center):**
* **Input:** Receives input from the "Rollout" stage.
* **Reference Model:** A box labeled "Reference Model."
* **Reward Model:** A box labeled "Reward Model."
* **Overlapped Execution:** A dashed box labeled "Overlapped Execution" containing:
* Code Executor
* Answer Matcher
* Format Checker
* An ellipsis (...) indicating more components.
* **Rule-based Reward:** The "Overlapped Execution" block is labeled "Rule-based Reward."
* **Output:** The output of the "Inference" stage feeds into the "Train" stage.
**3. Train Stage (Top-Right):**
* **Input:** Receives input from the "Inference" stage.
* **RL Algorithms:** A dashed box labeled "RL Algorithms" containing:
* PPO
* GRPO
* DPO
* An ellipsis (...) indicating more algorithms.
* **Pack Data:** The "RL Algorithms" block is labeled "Pack Data."
* **Actor Model:** A box labeled "Actor Model."
* **Critic Model (Optional):** A dashed box labeled "Critic Model (Optional)."
* **Update Parameters:** An arrow loops from the "Actor Model" back into itself, labeled "Update Parameters."
**4. VRAM Management (Bottom):**
* **Left Section:**
* "vLLM Workers" box.
* "Instantiate" arrow pointing to an "Actor" box.
* "Save & Offload Memory/Disk" arrow pointing from the "Actor" box to a box labeled "Actor" inside a "VRAM" box.
* **Middle Section:**
* "Destroy vLLM Workers" box.
* "Reload" arrow pointing to a "Reference Reward" box.
* "Reference Reward" box inside a "VRAM" box.
* "Memory/Disk" box with a "Reference Reward" box.
* **Right Section:**
* "Reload" arrow pointing to an "Actor Critic" box.
* "Actor Critic" box inside a "VRAM" box.
* "Offload" arrow pointing from the "Actor Critic" box to a "Reference Reward" box.
* "Memory/Disk" box with a "Reference Reward" box.
### Key Observations
* The diagram illustrates a pipeline for training LLMs using reinforcement learning.
* The "Rollout" stage generates data using "vLLM Workers" based on "Prompts."
* The "Inference" stage evaluates the generated data using "Reference" and "Reward" models.
* The "Train" stage updates the "Actor" model based on the rewards and uses a "Critic" model (optionally).
* "VRAM Management" shows how models are instantiated, saved/offloaded, destroyed, and reloaded between VRAM and Memory/Disk.
### Interpretation
The diagram depicts a sophisticated reinforcement learning workflow designed for training large language models. The separation into "Rollout," "Inference," and "Train" stages allows for modularity and optimization. The "VRAM Management" section highlights the importance of efficient memory utilization when dealing with large models. The use of "Reference" and "Reward" models in the "Inference" stage suggests a comparative evaluation process. The "Overlapped Execution" block indicates parallel processing for faster evaluation. The optional "Critic Model" suggests flexibility in the training approach. The diagram emphasizes the iterative nature of reinforcement learning through the "Update Parameters" loop. The presence of multiple RL algorithms (PPO, GRPO, DPO) indicates the potential for experimentation and optimization of the training process.