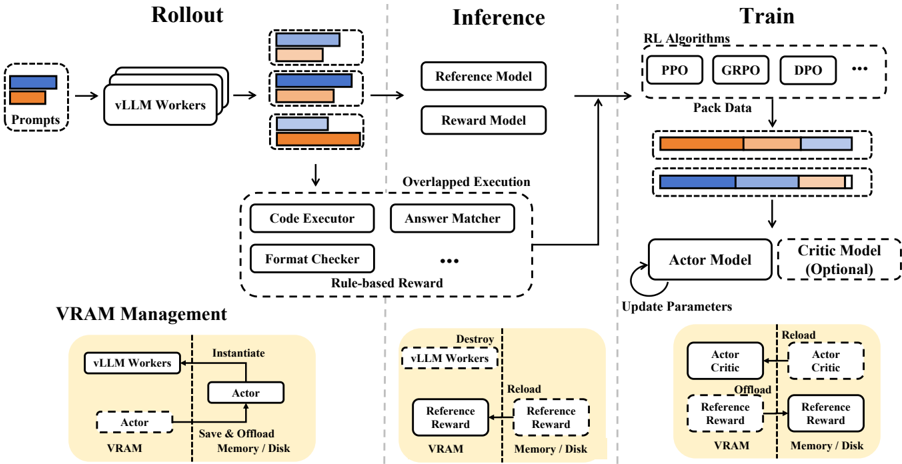
## System Architecture Diagram: Reinforcement Learning Training Pipeline for Large Language Models
### Overview
This image is a technical system architecture diagram illustrating a reinforcement learning (RL) training pipeline designed for large language models (LLMs). The diagram is divided into four main functional regions: **Rollout**, **Inference**, **Train**, and **VRAM Management**. It depicts the flow of data and control through various components, emphasizing an "Overlapped Execution" strategy and detailed VRAM (Video RAM) management for efficient resource utilization during training.
### Components/Axes
The diagram is organized into distinct sections with labeled boxes, arrows indicating data/control flow, and dashed lines grouping related components.
**1. Main Flow (Top Section):**
* **Rollout (Left):**
* Input: `Prompts` (represented by a stack of blue and orange rectangles).
* Processing Unit: `vLLM Workers` (a stack of three rounded rectangles).
* Output: A stack of three data blocks, each containing blue, orange, and brown segments.
* **Inference (Center):**
* Models: `Reference Model` and `Reward Model` (two rounded rectangles).
* Overlapped Execution Block (dashed outline): Contains `Code Executor`, `Answer Matcher`, `Format Checker`, and an ellipsis (`...`) indicating other components. This block is labeled `Rule-based Reward`.
* **Train (Right):**
* Algorithms: `RL Algorithms` (dashed box containing `PPO`, `GRPO`, `DPO`, and `...`).
* Data Processing: `Pack Data` leading to two packed data blocks (blue/orange/brown segments).
* Training Models: `Actor Model` (solid box with a self-referential arrow labeled `Update Parameters`) and `Critic Model (Optional)` (dashed box).
**2. VRAM Management (Bottom Section):**
This section is divided into three panels by vertical dashed lines, illustrating different states of component lifecycle and memory management.
* **Left Panel (Instantiation):** Shows `vLLM Workers` and `Actor` model being instantiated into `VRAM`. An arrow labeled `Save & Offload` points from `Actor` to `Memory / Disk`.
* **Center Panel (Destruction/Reload):** Shows `vLLM Workers` being destroyed (dashed box with an 'X'). `Reference` and `Reward` models are shown being reloaded from `Memory / Disk` into `VRAM`.
* **Right Panel (Offload/Reload):** Shows `Actor Critic` and `Reference Reward` components. Arrows indicate `Offload` from `VRAM` to `Memory / Disk` and `Reload` back into `VRAM`.
### Detailed Analysis
**Data Flow and Color Coding:**
* The diagram uses a consistent color scheme for data blocks: **blue**, **orange**, and **brown** segments. These likely represent different types of data or outputs (e.g., prompts, generated responses, rewards).
* **Flow Path:** `Prompts` -> `vLLM Workers` (Rollout) -> Data Blocks -> `Reference Model` & `Reward Model` / `Overlapped Execution` (Inference) -> `RL Algorithms` -> `Pack Data` -> `Actor Model` (Train).
* The `Overlapped Execution` block suggests that rule-based reward computation (via Code Executor, Answer Matcher, etc.) happens in parallel or in an interleaved manner with model inference to improve efficiency.
**VRAM Management Details:**
* The system dynamically manages GPU memory (VRAM). Components like `vLLM Workers`, the `Actor` model, and `Reference/Reward` models are not permanently resident in VRAM.
* **Key Operations:**
* `Instantiate`: Load a component into VRAM.
* `Save & Offload`: Move a component's state from VRAM to slower system memory or disk.
* `Destroy`: Remove a component from VRAM entirely.
* `Reload`: Bring a component back from memory/disk into VRAM.
* This management is crucial for training large models where the combined memory footprint of all components (actor, critic, reference, reward models, and inference workers) would exceed available VRAM.
### Key Observations
1. **Modular and Overlapping Design:** The architecture separates rollout, inference, and training into distinct but connected stages. The "Overlapped Execution" is a notable design choice to hide latency.
2. **Explicit Memory Management:** The dedicated VRAM Management section is a core feature, indicating this system is designed for resource-constrained environments or for scaling up model size beyond single-GPU capacity.
3. **Optional Critic:** The `Critic Model` is marked as `(Optional)`, suggesting the pipeline supports both actor-critic methods (like PPO) and potentially simpler policy gradient methods.
4. **Rule-Based Rewards:** The inclusion of `Code Executor`, `Answer Matcher`, and `Format Checker` indicates the reward signal is not solely from a neural `Reward Model` but can also be derived from deterministic, programmable rules.
### Interpretation
This diagram represents a sophisticated, production-oriented framework for RL-based fine-tuning of LLMs. The primary innovation highlighted is not just the training algorithm itself, but the **systems engineering** around it.
* **Purpose:** To enable the training of very large actor models by strategically offloading and reloading different system components (inference workers, reference models, reward models) to and from VRAM. This allows the scarce GPU memory to be focused on the active component—either the actor model during rollout/update or the critic/reference models during inference.
* **Relationships:** The `Rollout` and `Inference` stages generate the experiences (state-action-reward tuples) needed by the `Train` stage. The `VRAM Management` subsystem underpins all three, acting as a memory orchestrator. The `Overlapped Execution` block is a performance optimization that sits between inference and reward calculation.
* **Significance:** This architecture addresses a key bottleneck in RL for LLMs: memory. By treating VRAM as a managed resource with explicit load/store operations, it makes feasible the training of models that would otherwise be too large to fit alongside all necessary supporting components (reference model, reward model, inference engines) in GPU memory simultaneously. The design reflects a trend in ML systems where software-managed memory hierarchies are as critical as the algorithms themselves.