TECHNICAL ASSET FINGERPRINT
6523056266050d047c9f4324
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
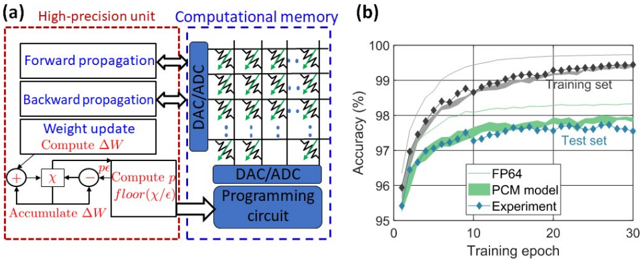
## Diagram and Chart: Neural Network Accelerator Architecture and Performance
### Overview
The image contains two distinct technical figures labeled (a) and (b). Figure (a) is a block diagram illustrating the architecture of a hybrid computing system that combines a high-precision processing unit with analog computational memory. Figure (b) is a line graph comparing the training accuracy over epochs for three different implementations of a neural network model.
### Components/Axes
**Figure (a) - Block Diagram:**
* **Left Block (Red Dashed Border):** Labeled "High-precision unit". Contains:
* Three main functional blocks: "Forward propagation", "Backward propagation", and "Weight update".
* A sub-block under "Weight update" labeled "Compute ΔW".
* A circuit diagram for weight accumulation, showing inputs `χ` and `ε`, a summation node (Σ), a floor function `floor(χ/ε)`, and an output `ΔW`.
* **Right Block (Blue Dashed Border):** Labeled "Computational memory". Contains:
* A crossbar array structure with green diagonal lines, representing a memory/processing matrix.
* A vertical block on the left of the array labeled "DAC/ADC" (Digital-to-Analog / Analog-to-Digital Converter).
* A horizontal block below the array labeled "DAC/ADC".
* A block at the bottom labeled "Programming circuit".
* **Connections:** Bidirectional arrows connect the "Forward propagation" and "Backward propagation" blocks to the vertical DAC/ADC. A unidirectional arrow connects the "Weight update" block to the "Programming circuit".
**Figure (b) - Line Graph:**
* **Title:** None visible.
* **Y-axis:** Label: "Accuracy (%)". Scale: 95 to 100, with major ticks at 95, 96, 97, 98, 99, 100.
* **X-axis:** Label: "Training epoch". Scale: 0 to 30, with major ticks at 0, 10, 20, 30.
* **Legend (Bottom-right corner):**
* Solid gray line: "FP64"
* Green shaded band: "PCM model"
* Blue diamond marker: "Experiment"
* **Data Series:** Two distinct groups of lines are plotted, annotated directly on the graph:
* **"Training set"** (Upper group of lines).
* **"Test set"** (Lower group of lines).
### Detailed Analysis
**Figure (a) - Architecture Flow:**
The diagram depicts a system where high-precision digital units handle forward and backward propagation (inference and error calculation). The computed weight updates (`ΔW`) are sent to a "Programming circuit" which likely adjusts the conductance states in the analog computational memory crossbar. The crossbar, with its integrated DAC/ADC, performs the core matrix-vector multiplication operations for the next forward pass, creating a closed-loop training accelerator.
**Figure (b) - Performance Data:**
* **Trend Verification:** All three data series (FP64, PCM model, Experiment) for both Training and Test sets show a logarithmic-like growth trend. Accuracy increases rapidly in the first ~5 epochs, then the rate of improvement slows, plateauing after approximately 20 epochs.
* **Training Set Performance (Upper Lines):**
* **FP64 (Solid Gray Line):** Starts at ~96.0% at epoch 0. Rises steeply, crossing 99% around epoch 10. Plateaus at approximately **99.4% - 99.5%** from epoch 20 to 30.
* **PCM model (Green Shaded Band):** Follows a very similar trajectory to FP64 but is consistently slightly lower. It plateaus at approximately **99.2% - 99.3%**. The shaded band indicates a small range of variance or confidence interval.
* **Experiment (Blue Diamond Markers):** The discrete data points closely track the upper edge of the PCM model band. The final experimental point at epoch 30 is at approximately **99.3%**.
* **Test Set Performance (Lower Lines):**
* **FP64 (Solid Gray Line):** Starts at ~95.8%. Rises to cross 97% around epoch 5. Plateaus at approximately **98.2% - 98.3%**.
* **PCM model (Green Shaded Band):** Again follows the FP64 trend but with a more noticeable gap. It plateaus at approximately **97.6% - 97.8%**.
* **Experiment (Blue Diamond Markers):** The experimental points align well with the PCM model's shaded region, ending at approximately **97.7%** at epoch 30.
### Key Observations
1. **Generalization Gap:** For all three implementations (FP64, PCM model, Experiment), there is a consistent gap of about **1.0% - 1.5%** between final training set accuracy (~99.3%) and final test set accuracy (~97.7%). This is a standard indicator of model overfitting.
2. **Model Fidelity:** The "PCM model" (likely a simulation of the analog hardware) and the physical "Experiment" results show excellent agreement, with experimental points falling within or on the boundary of the model's predicted variance band.
3. **Precision Impact:** The ideal "FP64" (64-bit floating-point) simulation achieves the highest accuracy on both sets. The analog-inspired PCM model and hardware experiment incur a small but measurable accuracy penalty, approximately **0.2% on the training set** and **0.5% on the test set** at convergence.
4. **Convergence Speed:** All models converge rapidly, achieving over 98% of their final accuracy within the first 10 epochs.
### Interpretation
This composite figure presents a compelling case for an analog AI accelerator. Figure (a) explains the *how*: a specialized architecture that offloads dense linear algebra (the core of neural networks) to energy-efficient analog computational memory, while keeping critical control and precision tasks in a digital unit. Figure (b) demonstrates the *effectiveness*: the proposed hardware ("Experiment") and its corresponding simulation ("PCM model") can train a neural network to an accuracy level that is very close to an ideal, high-precision digital baseline ("FP64").
The key takeaway is the **trade-off between precision and efficiency**. The system sacrifices a marginal amount of accuracy (less than 0.5% on test data) for what is implied to be significant gains in speed and energy efficiency, inherent to analog computing. The strong correlation between the PCM model and experimental data validates the design methodology and suggests the performance is predictable and reliable. The observed generalization gap is a property of the neural network task itself, not the hardware, indicating the analog accelerator does not introduce unique overfitting pathologies. This data supports the viability of using such hybrid analog-digital systems for practical, large-scale AI training workloads.
DECODING INTELLIGENCE...