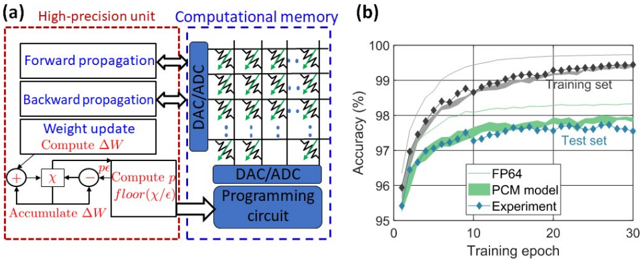
## Diagram and Chart: High-Precision Unit and Training Accuracy Analysis
### Overview
The image contains two components:
1. **Diagram (a)**: A technical flowchart depicting a high-precision unit and computational memory system.
2. **Graph (b)**: A line chart showing training accuracy over epochs for three data series (FP64, PCM model, Experiment).
---
### Components/Axes
#### Diagram (a)
- **Labels**:
- **High-precision unit** (red dashed box):
- Forward propagation
- Backward propagation
- Weight update
- Compute ΔW
- Accumulate ΔW
- Compute p
- floor(χ/ε)
- **Computational memory** (blue dashed box):
- DAC/ADC (Digital-to-Analog/Analog-to-Digital converters)
- Programming circuit
- **Flow**:
- Forward/backward propagation → Weight update → Compute ΔW → Accumulate ΔW → Compute p → floor(χ/ε) → DAC/ADC → Programming circuit.
#### Graph (b)
- **Axes**:
- **X-axis**: Training epoch (0–30, linear scale).
- **Y-axis**: Accuracy (%) (95–100, linear scale).
- **Legend**:
- **FP64** (gray line)
- **PCM model** (green line)
- **Experiment** (blue diamonds)
---
### Detailed Analysis
#### Diagram (a)
- **Textual elements**:
- "Forward propagation" and "Backward propagation" are labeled with bidirectional arrows.
- "Weight update" includes a summation symbol (+) and a subtraction symbol (−).
- "Compute ΔW" and "Accumulate ΔW" are connected via a feedback loop.
- "Compute p" and "floor(χ/ε)" are linked to the DAC/ADC block.
- **Spatial grounding**:
- The high-precision unit is on the left, computational memory in the center, and programming circuit on the right.
#### Graph (b)
- **Data series**:
- **FP64** (gray line): Starts at ~95% accuracy, rises to ~99.5% by epoch 30.
- **PCM model** (green line): Starts at ~95%, increases to ~98% by epoch 30.
- **Experiment** (blue diamonds): Starts at ~95%, fluctuates between ~96–97.5%, converging to ~97.5% by epoch 30.
- **Trends**:
- FP64 shows the steepest upward slope.
- PCM model and Experiment exhibit slower, more gradual improvements.
- All series converge toward higher accuracy as epochs increase.
---
### Key Observations
1. **FP64 dominates**: The gray line (FP64) consistently outperforms other series, reaching near-100% accuracy.
2. **PCM model vs. Experiment**: The green line (PCM model) and blue diamonds (Experiment) show similar trends but with lower final accuracy (~98% vs. ~97.5%).
3. **Convergence**: All series plateau near 97–99.5% accuracy by epoch 30, suggesting diminishing returns after initial training.
---
### Interpretation
- **Technical implications**:
- The high-precision unit (diagram a) likely enables FP64's superior performance by optimizing weight updates and error computation.
- The PCM model and Experiment may represent alternative architectures or hardware implementations, with slightly lower efficiency.
- **Training dynamics**:
- The graph highlights the importance of epoch count for model convergence. FP64 achieves near-optimal accuracy faster than other methods.
- **Anomalies**:
- The Experiment's fluctuating accuracy (blue diamonds) suggests potential instability or noise in the training process compared to the smoother PCM model.
This analysis underscores the role of precision in computational memory systems and their impact on machine learning training efficiency.