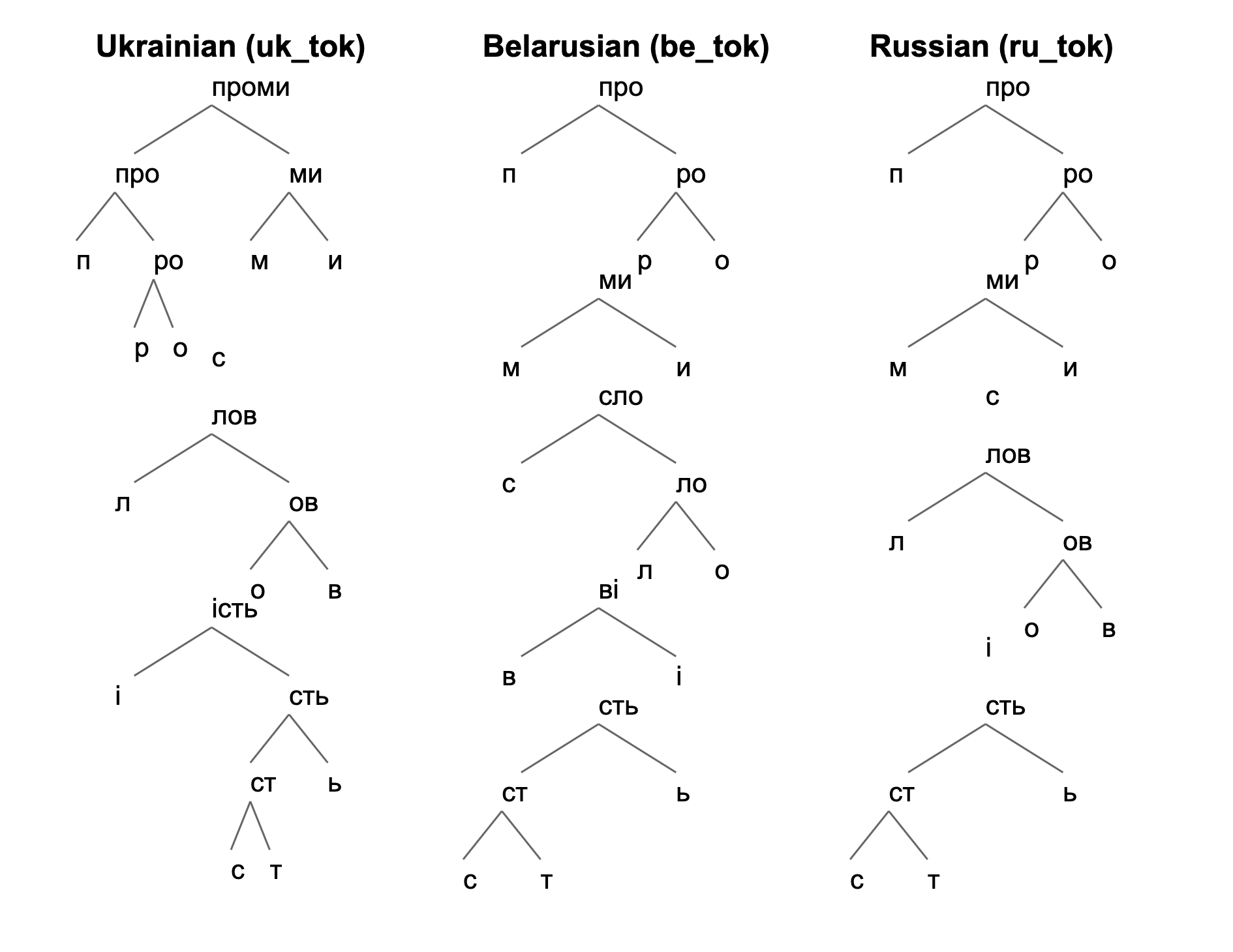
## Linguistic Diagram: Morphological Segmentation Trees for Slavic Languages
### Overview
The image displays three separate hierarchical tree diagrams, each illustrating the morphological segmentation (breaking down into constituent morphemes) of a word in a different Slavic language. The languages are Ukrainian, Belarusian, and Russian, identified by both their English names and token identifiers (`uk_tok`, `be_tok`, `ru_tok`). The diagrams are presented in three vertical columns against a plain white background.
### Components/Axes
The image is divided into three distinct vertical sections, each with a title and a tree diagram below it.
1. **Left Column:**
* **Title:** `Ukrainian (uk_tok)`
* **Tree Root:** `проми`
* **Structure:** A binary branching tree decomposing the root into smaller morphemes and ultimately individual characters.
2. **Center Column:**
* **Title:** `Belarusian (be_tok)`
* **Tree Root:** `про`
* **Structure:** A binary branching tree with a different segmentation pattern compared to the Ukrainian tree.
3. **Right Column:**
* **Title:** `Russian (ru_tok)`
* **Tree Root:** `про`
* **Structure:** A binary branching tree that shares the same root as Belarusian but has a different internal structure.
**Language Declaration:** The primary language of the labels is English. The content of the tree diagrams is in Cyrillic script, representing Ukrainian, Belarusian, and Russian morphemes.
### Detailed Analysis
#### Ukrainian Tree (`uk_tok`)
* **Root:** `проми` (promy)
* **First Split:** Divides into `про` (pro) and `ми` (my).
* **Left Branch (`про`):** Further splits into `п` (p) and `ро` (ro). The node `ро` then splits into `р` (r) and `о` (o). A standalone character `с` (s) appears adjacent to this branch, though its connection is not explicitly drawn.
* **Right Branch (`ми`):** Splits into `м` (m) and `и` (i).
* **Lower Section:** A separate, disconnected tree structure appears below the main one.
* **Root:** `лов` (lov)
* **Splits:** `л` (l) and `ов` (ov). `ов` splits into `о` (o) and `в` (v).
* **Further Structure:** Below `ов`, the node `ість` (ist') appears, splitting into `i` (i) and `сть` (st'). `сть` splits into `ст` (st) and `ь` (soft sign). `ст` finally splits into `с` (s) and `т` (t).
#### Belarusian Tree (`be_tok`)
* **Root:** `про` (pro)
* **First Split:** Divides into `п` (p) and `ро` (ro).
* **Right Branch (`ро`):** Splits into `р` (r) and `о` (o).
* **Left Branch (`п`):** Connects to a lower node `ми` (my).
* **Lower Structure:** The node `ми` splits into `м` (m) and `и` (i). Below this, the node `сло` (slo) appears, splitting into `с` (s) and `ло` (lo). `ло` splits into `л` (l) and `о` (o). The node `Ві` (Vi) appears, splitting into `В` (V) and `i` (i). Finally, the node `сть` (st') splits into `ст` (st) and `ь` (soft sign), with `ст` splitting into `с` (s) and `т` (t).
#### Russian Tree (`ru_tok`)
* **Root:** `про` (pro)
* **First Split:** Divides into `п` (p) and `ро` (ro).
* **Right Branch (`ро`):** Splits into `р` (r) and `о` (o).
* **Left Branch (`п`):** Connects to a lower node `ми` (my).
* **Lower Structure:** The node `ми` splits into `м` (m) and `и` (i). A standalone character `с` (s) appears below. The node `лов` (lov) appears, splitting into `л` (l) and `ов` (ov). `ов` splits into `о` (o) and `в` (v). The node `i` (i) appears standalone. Finally, the node `сть` (st') splits into `ст` (st) and `ь` (soft sign), with `ст` splitting into `с` (s) and `т` (t).
### Key Observations
1. **Shared Roots:** Belarusian and Russian share the same root morpheme `про` (pro), while Ukrainian has the longer root `проми` (promy).
2. **Divergent Segmentation:** Despite the shared root, the internal tree structures for Belarusian and Russian differ significantly, especially in the lower, more complex segments.
3. **Common Sub-Morphemes:** All three trees contain the sub-structures `ми` (my), `лов` (lov), and `сть` (st'), though their placement and connections within the overall tree vary.
4. **Character-Level Decomposition:** All trees ultimately decompose morphemes into individual Cyrillic characters (e.g., `ст` -> `с` + `т`).
5. **Visual Layout:** The trees are not perfectly aligned vertically. The Ukrainian tree is the tallest. The Belarusian and Russian trees have similar heights but different internal node arrangements. Some characters (`с` in Ukrainian, `с` and `i` in Russian) appear as isolated leaves without explicit parent lines in the provided diagram.
### Interpretation
This diagram is a technical representation used in computational linguistics or natural language processing (NLP), specifically for **morphological analysis** or **subword tokenization**. The trees likely visualize the output of a segmentation algorithm (like Byte-Pair Encoding or a linguistic parser) applied to cognate words across closely related languages.
* **What it demonstrates:** It shows how the same or similar semantic concepts (potentially related to "about us" or "pro-" prefix + "we") are morphologically structured in three East Slavic languages. The differences highlight language-specific morphological rules and historical sound changes.
* **Relationship between elements:** The hierarchical trees represent a hypothesis about the compositional structure of words. Parent nodes are hypothesized to be formed by combining their child nodes. The comparison across languages allows researchers to study morphological divergence and alignment.
* **Notable anomalies:** The disconnected characters (`с` in Ukrainian, `с` and `i` in Russian) are peculiar. They might represent artifacts of the tokenization process, noise in the data, or a specific notation where certain characters are treated as separate tokens without being part of a larger morpheme in this particular analysis. The presence of the Latin character `i` in the Russian tree is also notable, possibly indicating a loanword element or a specific tokenization choice.
* **Underlying purpose:** Such visualizations are crucial for building multilingual language models, understanding cross-lingual transfer, and developing language-specific NLP tools. They provide a window into how a model "sees" and breaks down words, which is fundamental for tasks like machine translation, text generation, and information retrieval.