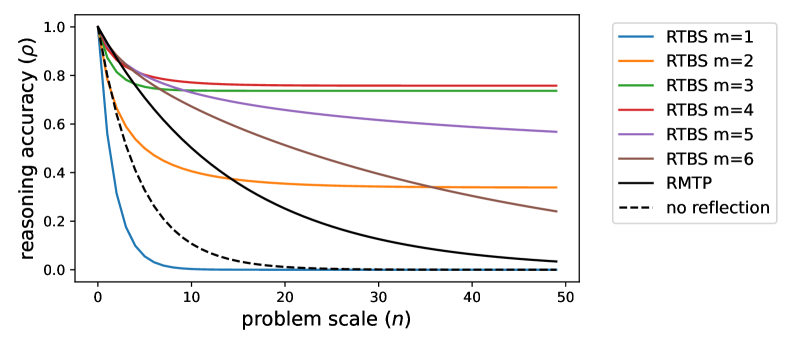
## Line Graph: Reasoning Accuracy vs. Problem Scale
### Overview
The graph illustrates the relationship between reasoning accuracy (ρ) and problem scale (n) for different computational models. Accuracy declines as problem scale increases, with distinct performance patterns across models.
### Components/Axes
- **Y-axis**: Reasoning accuracy (ρ) ranging from 0.0 to 1.0 in increments of 0.2.
- **X-axis**: Problem scale (n) ranging from 0 to 50 in increments of 10.
- **Legend**: Positioned in the top-right corner, containing:
- RTBS models (m=1 to m=6) with solid colored lines (blue, orange, green, red, purple, brown).
- RMTP (solid black line).
- "no reflection" (dashed black line).
### Detailed Analysis
1. **RTBS Models (m=1 to m=6)**:
- All RTBS lines start at ρ=1.0 when n=0.
- Accuracy declines sharply for lower m values (e.g., m=1 drops to ~0.2 by n=10).
- Higher m values (m=4–6) maintain higher accuracy longer (e.g., m=6 retains ~0.6 at n=50).
- Lines are ordered by color: m=1 (blue) → m=6 (brown).
2. **RMTP**:
- Solid black line starts at ρ=1.0 and declines gradually to ~0.1 by n=50.
- Outperforms "no reflection" but lags behind RTBS models with m≥3.
3. **No Reflection**:
- Dashed black line remains near ρ=0.05 across all n values.
- Shows minimal improvement even at n=0.
### Key Observations
- **RTBS Scaling**: Higher m values correlate with better performance on larger problem scales.
- **RMTP vs. No Reflection**: RMTP significantly outperforms "no reflection" but is less effective than RTBS models with m≥3.
- **Steepest Declines**: Lower m RTBS models (m=1–2) experience the fastest accuracy drops.
### Interpretation
The data suggests that increasing the parameter m in RTBS models enhances reasoning accuracy for larger problem scales, likely due to improved computational capacity or parameter efficiency. RMTP provides moderate performance, while "no reflection" is ineffective. The sharpest declines in lower m RTBS models highlight the importance of model complexity for scalability. This trend underscores the trade-off between model size and generalization in reasoning tasks.