TECHNICAL ASSET FINGERPRINT
65b01a9e8372b185dcea07f8
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
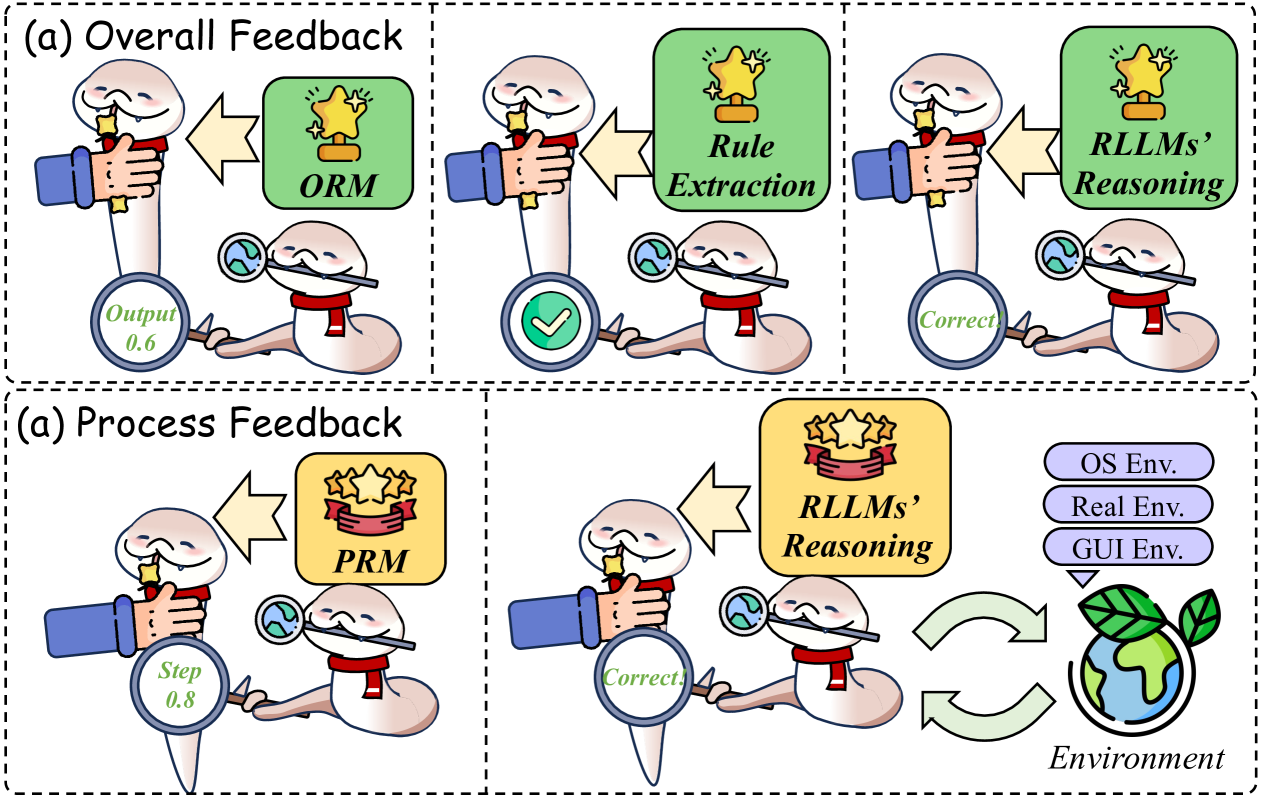
## Diagram: Feedback Mechanisms in AI Reasoning Systems
### Overview
The image is a conceptual diagram illustrating two distinct feedback mechanisms for evaluating and improving AI reasoning systems, specifically referred to as "RLLMs" (Reasoning Large Language Models). The diagram is divided into two horizontal panels, each enclosed by a dashed border. The top panel is labeled "(a) Overall Feedback," and the bottom panel is labeled "(a) Process Feedback" (note: the duplicate label "(a)" appears to be a typographical error in the source image). The diagram uses cartoon-style illustrations of a worm-like character with a magnifying glass (representing an evaluator or critic) and a hand holding a trophy (representing a reward or scoring model) to depict the flow of information and feedback.
### Components/Axes
The diagram is not a chart with axes but a process flow diagram. Its key components are:
**Top Panel: (a) Overall Feedback**
* **Title:** "(a) Overall Feedback" (top-left corner).
* **Three Sequential Stages:** Arranged left to right, each stage shows an interaction between the "evaluator" worm and a "reward" hand.
1. **Stage 1 (Left):**
* **Reward Model Box:** Green box labeled "ORM" (likely Outcome Reward Model).
* **Output Magnifying Glass:** Held by the worm, displays "Output 0.6".
2. **Stage 2 (Center):**
* **Reward Model Box:** Green box labeled "Rule Extraction".
* **Output Magnifying Glass:** Held by the worm, displays a green checkmark icon.
3. **Stage 3 (Right):**
* **Reward Model Box:** Green box labeled "RLLMs' Reasoning".
* **Output Magnifying Glass:** Held by the worm, displays the word "Correct".
**Bottom Panel: (a) Process Feedback**
* **Title:** "(a) Process Feedback" (top-left corner).
* **Two Main Stages & Environment Loop:** Arranged left to right.
1. **Stage 1 (Left):**
* **Reward Model Box:** Yellow box labeled "PRM" (likely Process Reward Model).
* **Step Magnifying Glass:** Held by the worm, displays "Step 0.8".
2. **Stage 2 (Center):**
* **Reward Model Box:** Yellow box labeled "RLLMs' Reasoning".
* **Output Magnifying Glass:** Held by the worm, displays the word "Correct".
3. **Environment Component (Right):**
* **Environment Label:** Text "Environment" at the bottom.
* **Globe Icon:** A stylized Earth with leaves.
* **Environment Type Labels:** Three stacked, rounded rectangles in light purple, labeled from top to bottom: "OS Env.", "Real Env.", "GUI Env.".
* **Interaction Arrows:** Two curved, green arrows form a loop between the "RLLMs' Reasoning" stage and the "Environment" globe, indicating continuous interaction.
### Detailed Analysis
The diagram contrasts two evaluation paradigms:
1. **Overall Feedback (Top Panel):** This process evaluates the final outcome of a reasoning task.
* **Flow:** The process moves sequentially from left to right.
* **Trend/Progression:** The feedback becomes more refined. It starts with a numerical score ("Output 0.6") from an ORM, progresses to a rule-based verification (checkmark from "Rule Extraction"), and culminates in a definitive "Correct" judgment based on the RLLMs' own reasoning.
* **Color Coding:** All reward model boxes in this panel are green.
2. **Process Feedback (Bottom Panel):** This process evaluates intermediate steps and involves interaction with an external environment.
* **Flow:** It shows a step-wise evaluation and a cyclical interaction with the environment.
* **Trend/Progression:** It begins with a step-level score ("Step 0.8") from a PRM, leads to a "Correct" judgment from the RLLMs' Reasoning, and then enters a loop with the Environment.
* **Environment Interaction:** The RLLMs' reasoning interacts with three types of environments: Operating System (OS Env.), Real-world (Real Env.), and Graphical User Interface (GUI Env.). The loop suggests an iterative process of action and observation.
* **Color Coding:** Reward model boxes in this panel are yellow. Environment labels are light purple.
### Key Observations
* **Duplicate Labeling:** Both main panels are labeled "(a)", which is likely an error in the original figure.
* **Visual Metaphor:** The consistent use of the worm with a magnifying glass symbolizes scrutiny and evaluation. The hand offering a trophy symbolizes reward or scoring.
* **Score vs. Binary Judgment:** The initial stages provide numerical scores (0.6, 0.8), while the final stages in both panels provide a binary "Correct" judgment.
* **Complexity:** The "Process Feedback" model is more complex, incorporating an explicit, multi-faceted environment and a feedback loop, whereas "Overall Feedback" is a linear, self-contained sequence.
* **Acronyms:** Key technical terms are presented as acronyms: ORM, PRM, RLLMs, OS, GUI.
### Interpretation
This diagram illustrates a conceptual framework for training or evaluating reasoning AI models. It argues for a distinction between two levels of feedback:
* **Overall Feedback** is akin to grading a final exam. It looks at the end result ("Output") and may use intermediate steps like rule checking, but the reward signal is tied to the final outcome. The progression from a low score (0.6) to "Correct" suggests a process of refinement or learning based on this outcome-based reward.
* **Process Feedback** is akin to a tutor guiding a student through each step of a problem. It provides feedback ("Step 0.8") on the reasoning process itself, not just the answer. Crucially, it places the AI's reasoning within an interactive loop with diverse environments (digital OS/GUI and physical "Real Env."). This suggests the model learns by taking actions, observing consequences in these environments, and receiving step-wise rewards. The higher initial step score (0.8 vs. 0.6) might imply that process-level feedback provides a stronger or more immediate learning signal.
The overall message is that while outcome-based evaluation (Overall Feedback) is important, a more sophisticated and potentially more effective paradigm involves evaluating and rewarding the reasoning process itself, especially when that process is grounded in interaction with realistic environments (Process Feedback). This aligns with trends in AI research towards process reward models and embodied or interactive learning.
DECODING INTELLIGENCE...