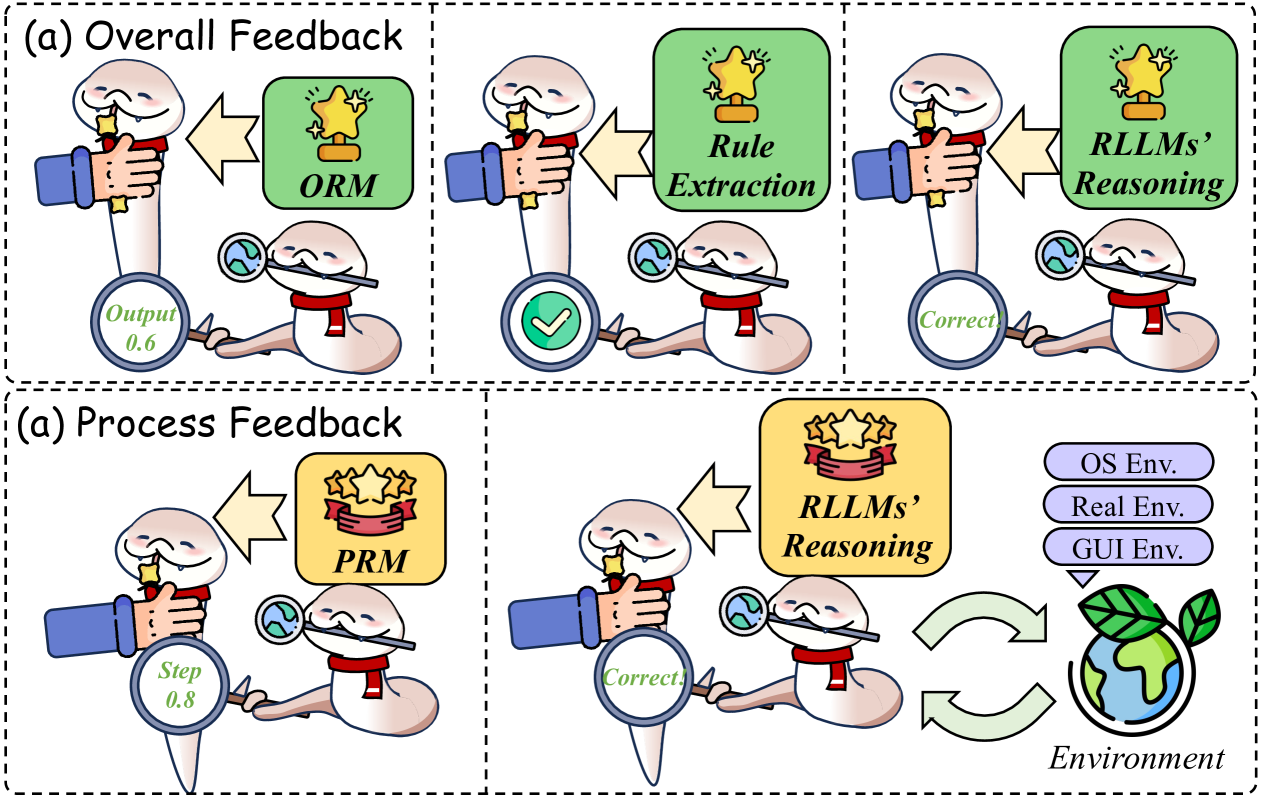
## Diagram: Multi-Stage Feedback and Reasoning Process
### Overview
The diagram illustrates a two-phase feedback system involving a cartoon character (likely representing an AI or agent) interacting with a human hand and various evaluation components. The system is divided into **Overall Feedback** (top row) and **Process Feedback** (bottom row), each with three sequential steps. Key elements include performance metrics (ORM, PRM), reasoning models (RLLMs), and environmental interactions (OS, Real, GUI).
---
### Components/Axes
1. **Overall Feedback** (Top Row):
- **Step 1**: Human hand interacts with character → **ORM** (Output: 0.6, star icon).
- **Step 2**: Character uses magnifying glass → **Rule Extraction** (green checkmark, "Correct!").
- **Step 3**: Character evaluates output → **RLLMs’ Reasoning** (star icon, "Correct!").
2. **Process Feedback** (Bottom Row):
- **Step 1**: Human hand interacts with character → **PRM** (three stars, step value: 0.8).
- **Step 2**: Character uses magnifying glass → **RLLMs’ Reasoning** (green checkmark, "Correct!").
- **Step 3**: Character interacts with **Environment** (OS, Real, GUI Env, bidirectional arrows).
3. **Environment**:
- Three ovals labeled **OS Env**, **Real Env**, **GUI Env** connected by green arrows, forming a cyclical loop.
---
### Detailed Analysis
- **Labels/Text**:
- **ORM**: Output Rating Model (0.6 score).
- **PRM**: Process Rating Model (0.8 score, three stars).
- **RLLMs’ Reasoning**: Recurrent Large Language Models’ Reasoning (appears in both phases).
- **Environment**: Three sub-components (OS, Real, GUI) with bidirectional arrows indicating dynamic interaction.
- **Flow**:
- **Overall Feedback**: Linear progression from ORM → Rule Extraction → RLLMs’ Reasoning.
- **Process Feedback**: Linear progression from PRM → RLLMs’ Reasoning → Environment.
- **Environment**: Cyclical interaction between OS, Real, and GUI environments.
- **Visual Elements**:
- **Stars**: Represent performance ratings (e.g., PRM has three stars vs. ORM’s single star).
- **Checkmarks**: Indicate correctness validation (Rule Extraction and RLLMs’ Reasoning).
- **Magnifying Glass**: Symbolizes detailed scrutiny (used in both phases).
---
### Key Observations
1. **Recurring Elements**: RLLMs’ Reasoning appears in both feedback phases, suggesting it is a central validation mechanism.
2. **Performance Metrics**:
- ORM (0.6) and PRM (0.8) quantify output and process quality, respectively.
- PRM’s higher score (0.8) implies process evaluation is more rigorous.
3. **Environmental Interaction**: The cyclical arrows between OS, Real, and GUI Env suggest iterative testing across different contexts.
---
### Interpretation
The diagram represents a **multi-layered evaluation framework** for an AI system:
1. **Overall Feedback** focuses on high-level output quality (ORM) and rule-based validation (Rule Extraction), with RLLMs’ Reasoning acting as a final correctness check.
2. **Process Feedback** emphasizes granular process evaluation (PRM) and detailed reasoning validation, followed by real-world environmental testing.
3. **Environmental Interaction**: The bidirectional arrows between OS, Real, and GUI Env imply that the system adapts or is tested across operational, real-world, and user interface contexts, creating a feedback loop for continuous improvement.
**Notable Trends**:
- The use of stars and checkmarks visually reinforces performance and correctness.
- The higher PRM score (0.8) vs. ORM (0.6) suggests process evaluation is prioritized over output quality in this framework.
- RLLMs’ Reasoning serves as a bridge between feedback phases, ensuring consistency in validation.
This structure highlights the importance of iterative, multi-dimensional evaluation in AI systems, balancing quantitative metrics (ORM/PRM) with qualitative reasoning and environmental adaptability.