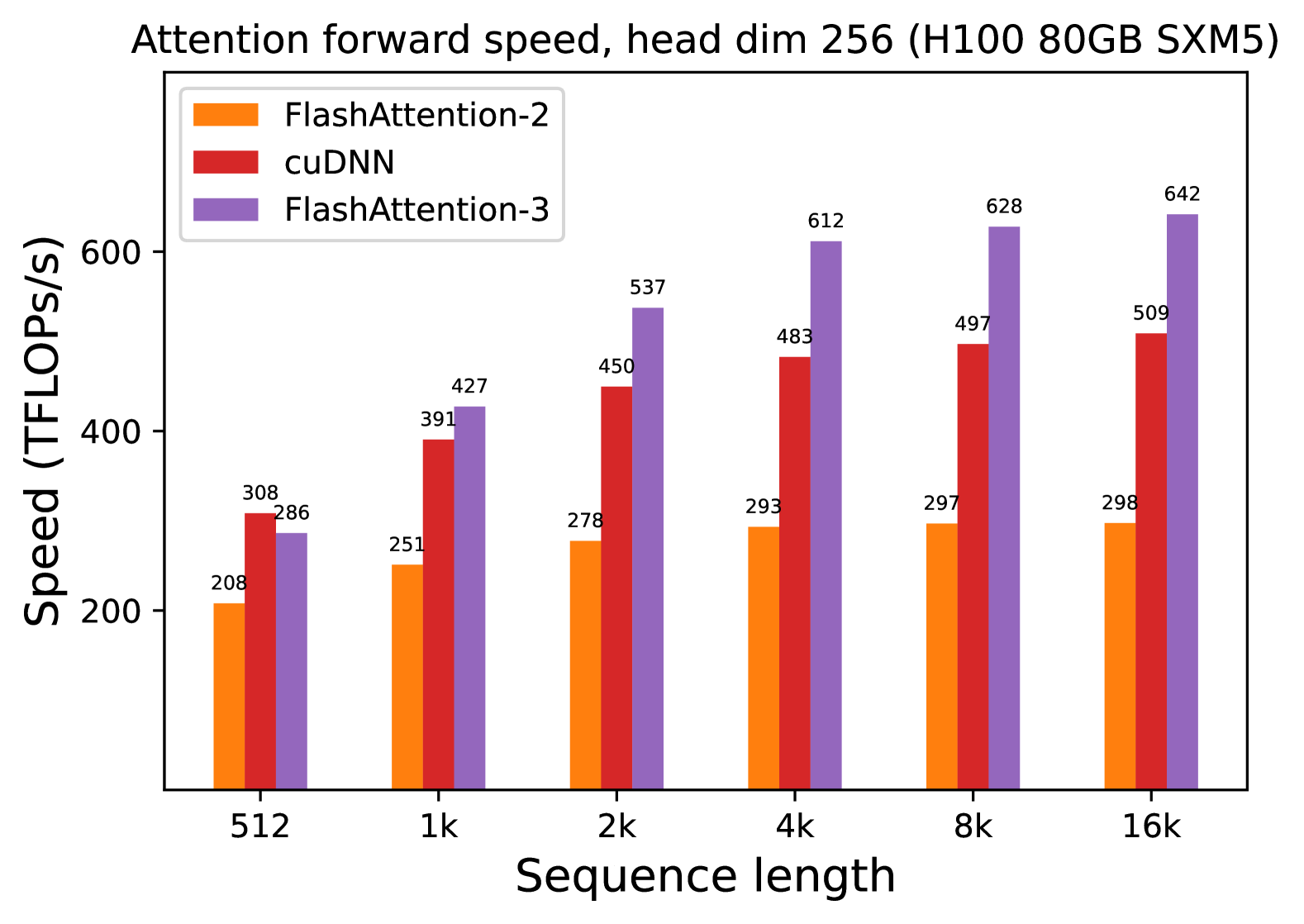
# Technical Document Extraction: Attention Forward Speed Analysis
## Chart Title
**Attention forward speed, head dim 256 (H100 80GB SXM5)**
## Axis Labels
- **X-axis**: Sequence length (categories: 512, 1k, 2k, 4k, 8k, 16k)
- **Y-axis**: Speed (TFLOPs/s)
## Legend
| Color | Method |
|--------|-------------------|
| Orange | FlashAttention-2 |
| Red | cuDNN |
| Purple | FlashAttention-3 |
## Data Points (Speed in TFLOPs/s)
| Sequence Length | FlashAttention-2 | cuDNN | FlashAttention-3 |
|-----------------|------------------|-------|------------------|
| 512 | 208 | 308 | 286 |
| 1k | 251 | 391 | 427 |
| 2k | 278 | 450 | 537 |
| 4k | 293 | 483 | 612 |
| 8k | 297 | 497 | 628 |
| 16k | 298 | 509 | 642 |
## Key Trends
1. **Performance Scaling**: All methods show increased speed with longer sequence lengths.
2. **Method Comparison**:
- **FlashAttention-3** consistently outperforms other methods across all sequence lengths (e.g., 642 TFLOPs/s at 16k vs. 509 TFLOPs/s for cuDNN).
- **cuDNN** outperforms **FlashAttention-2** in all cases (e.g., 308 TFLOPs/s at 512 vs. 208 TFLOPs/s).
- **FlashAttention-3** achieves ~20-30% higher speed than cuDNN at longer sequences (e.g., 612 TFLOPs/s at 4k vs. 483 TFLOPs/s).
3. **Diminishing Returns**: Speed gains per sequence length increase plateau slightly at 8k and 16k for all methods.
## Notes
- Data extracted directly from bar heights and legend labels.
- Colors in the chart strictly align with the legend (orange = FlashAttention-2, red = cuDNN, purple = FlashAttention-3).