\n
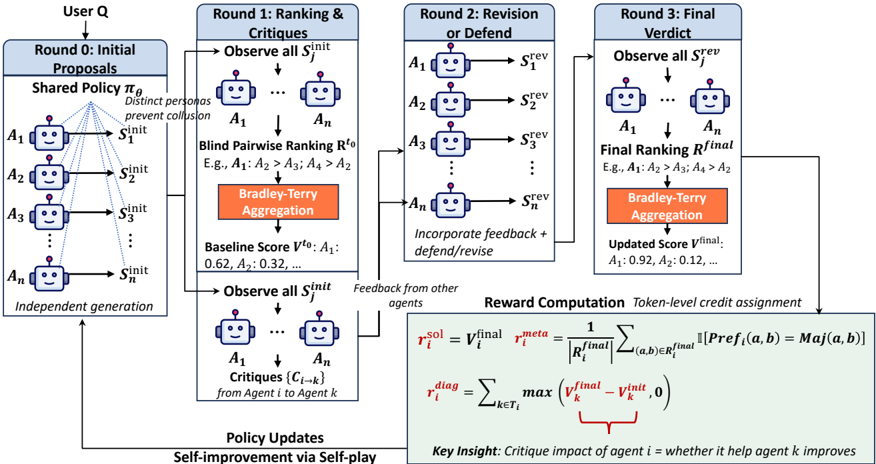
## Diagram: Iterative Agent Refinement Process
### Overview
This diagram illustrates an iterative process for refining agents (A1 to An) through rounds of proposal generation, ranking/critique, revision, and final verdict. The process involves a user (Q) and multiple agents interacting to improve their performance based on feedback and a Bradley-Terry aggregation method. The diagram is segmented into three main rounds, with a policy update step at the end.
### Components/Axes
The diagram is structured into four main sections:
1. **Round 0: Initial Proposals** (Leftmost column, light blue)
2. **Round 1: Ranking & Critiques** (Middle-left column, light blue)
3. **Round 2: Revision or Defend** (Middle-right column, orange)
4. **Round 3: Final Verdict** (Rightmost column, red)
Additionally, there's a section for **Reward Computation** and **Policy Updates** at the bottom.
Key labels include:
* **User Q**: The external evaluator.
* **A1...An**: Individual agents.
* **S¹init, S¹rev, S¹rev**: Initial and revised proposals from agents.
* **R⁰, R¹final**: Ranking results from each round.
* **V⁰, V¹final**: Baseline and updated scores for agents.
* **Critiques (C1→k)**: Feedback from agent 1 to agent k.
* **r¹sol, r¹meta, r¹diag**: Reward components.
* **πg**: Shared policy.
### Detailed Analysis or Content Details
**Round 0: Initial Proposals**
* A shared policy πg generates initial proposals (S¹init) for each agent (A1 to An).
* The agents are represented as boxes connected to their initial proposals.
* The agents are described as having "Distinct personas".
* The proposals are generated "Independent generation".
**Round 1: Ranking & Critiques**
* Agents observe all initial proposals (S¹init).
* A "Blind Pairwise Ranking R⁰" is performed (e.g., A1 > A2 > A3 > A4 > A2).
* "Bradley-Terry Aggregation" is used to calculate a "Baseline Score V⁰" for each agent (e.g., A1: 0.62, A2: 0.32,...).
* Agents observe all initial proposals (S¹init) again.
* Critiques (C1→k) are generated from each agent to every other agent.
**Round 2: Revision or Defend**
* Agents revise or defend their proposals based on feedback, resulting in revised proposals (S¹rev).
* The agents incorporate feedback and defend/revise.
**Round 3: Final Verdict**
* Agents observe all revised proposals (S¹rev).
* A "Final Ranking R¹final" is determined (e.g., A1 > A2 > A3 > A4 > A2).
* "Bradley-Terry Aggregation" is used again to calculate an "Updated Score V¹final" (e.g., A1: 0.92, A2: 0.12,...).
**Reward Computation**
* **r¹sol = V¹final - V⁰**: The difference between the final and baseline scores.
* **r¹meta = (1/R¹final) * Σ [(a,b)∈R¹final] [Pref(a,b) = Maj(a,b)]**: A meta-reward based on the agreement with the majority preference.
* **r¹diag = max(V¹final - V¹k)**: A diagnostic reward based on the maximum improvement over other agents.
**Policy Updates**
* Self-improvement via self-play.
**Key Insight:** Critique impact of agent i = whether it helped agent k improves.
### Key Observations
* The process is iterative, with each round building upon the previous one.
* The Bradley-Terry aggregation method is used in both Round 1 and Round 3.
* The reward computation involves multiple components, including a solution reward, a meta-reward, and a diagnostic reward.
* The diagram highlights the importance of critiques in driving agent improvement.
* The example rankings (R⁰ and R¹final) show a consistent preference order among the agents.
### Interpretation
This diagram describes a reinforcement learning framework where agents iteratively improve their performance through a process of proposal generation, critique, revision, and evaluation. The use of a Bradley-Terry aggregation method suggests a preference-based learning approach, where agents learn from pairwise comparisons. The reward computation mechanism incentivizes agents to both improve their own scores and contribute to the overall improvement of the system. The "Key Insight" emphasizes the role of critiques in facilitating agent learning. The diagram suggests a system designed for collaborative improvement, where agents benefit from both their own revisions and the feedback provided by others. The iterative nature of the process allows for continuous refinement and adaptation. The use of distinct personas for each agent suggests a focus on diversity and exploration in the solution space. The overall goal appears to be to develop a set of agents that can effectively generate and evaluate proposals, leading to improved performance over time. The diagram is a high-level overview of the process and does not provide specific details about the implementation of the agents or the ranking/critique mechanisms.