TECHNICAL ASSET FINGERPRINT
66910986738e21e65423169d
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
\n
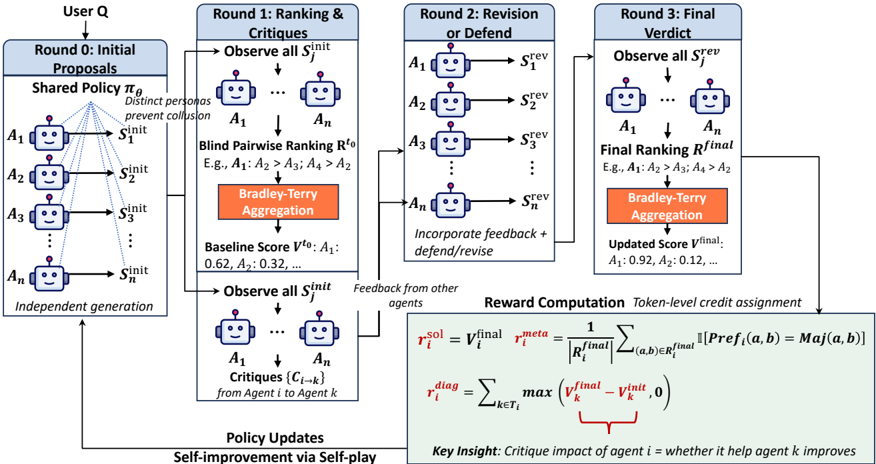
## Diagram: Multi-Agent Reinforcement Learning with Critique and Self-Play
### Overview
The image is a technical flowchart illustrating a multi-stage, multi-agent reinforcement learning framework. The process involves multiple AI agents (represented by robot icons) generating solutions, ranking each other's outputs, providing critiques, revising their work, and finally computing rewards for policy updates. The system is designed for self-improvement via self-play, where agents learn from their interactions and feedback.
### Components/Axes
The diagram is organized into five main vertical sections or "Rounds," connected by arrows indicating data flow.
**1. Leftmost Section: User Input & Initial Generation**
* **Label:** `User Q` (at the very top).
* **Component:** `Round 0: Initial Proposals`.
* **Process:** A `Shared Policy πθ` is used for `Independent generation` by `n` agents (`A1`, `A2`, `A3`, ..., `An`).
* **Output:** Each agent `Ai` produces an initial solution `S_i^init`.
* **Annotation:** `Distinct personas prevent collusion`.
**2. Second Section: Round 1 - Ranking & Critiques**
* **Label:** `Round 1: Ranking & Critiques`.
* **Process Flow:**
1. `Observe all S_j^init`: Agents `A1` to `An` observe all initial solutions.
2. `Blind Pairwise Ranking R^r0`: Agents perform ranking. An example is given: `E.g., A1: A2 > A3; A4 > A2`.
3. `Bradley-Terry Aggregation` (in an orange box): Rankings are aggregated.
4. `Baseline Score V^r0`: Aggregated scores are produced. An example is given: `A1: 0.62, A2: 0.32, ...`.
* **Parallel Process (Bottom of Round 1):**
1. `Observe all S_j^init`: Agents observe solutions again.
2. `Critiques {C_i->k}`: Agents generate critiques. Annotation: `from Agent i to Agent k`.
3. `Feedback from other agents`: This critique data flows to the next round.
**3. Third Section: Round 2 - Revision or Defend**
* **Label:** `Round 2: Revision or Defend`.
* **Process:** Agents `A1` to `An` receive feedback and either `defend/revise` their proposals.
* **Output:** Each agent produces a revised solution `S_i^rev`.
**4. Fourth Section: Round 3 - Final Verdict**
* **Label:** `Round 3: Final Verdict`.
* **Process Flow:**
1. `Observe all S_j^rev`: Agents observe all revised solutions.
2. `Final Ranking R^final`: Agents perform a final ranking. An example is given: `E.g., A1: A4 > A2 > A3; A2: A4 > A1 > A3`.
3. `Bradley-Terry Aggregation` (in an orange box): Final rankings are aggregated.
4. `Updated Score V^final`: Final aggregated scores are produced. An example is given: `A1: 0.92, A2: 0.12, ...`.
**5. Bottom Section: Reward Computation & Policy Update**
* **Label:** `Reward Computation` and `Token-level credit assignment`.
* **Mathematical Formulas:**
* `r_i^sal = V_i^final`
* `r_i^meta = (1 / |R_i^final|) * Σ_{(a,b) ∈ R_i^final} 1[Pref_i(a,b) = Maj(a,b)]`
* `r_i^diag = Σ_{k ∈ T_i} max(V_k^final - V_k^init, 0)`
* **Key Insight Annotation:** `Key Insight: Critique impact of agent i = whether it help agent k improves`. A red bracket connects this text to the `max(...)` term in the `r_i^diag` formula.
* **Final Output:** `Policy Updates` and `Self-improvement via Self-play`, with an arrow looping back to the `Shared Policy πθ` at the start.
### Detailed Analysis
The diagram details a sequential, three-round process following initial generation:
1. **Round 0 (Initialization):** Agents independently generate initial solutions using a shared policy, but with distinct personas to avoid collusion.
2. **Round 1 (Evaluation & Feedback):** Agents first rank each other's initial solutions blindly, which are aggregated into baseline scores (`V^r0`). Concurrently, they generate critiques for each other. This round establishes a performance baseline and provides feedback.
3. **Round 2 (Adaptation):** Agents use the critiques from Round 1 to either defend their original solution or revise it, producing `S_i^rev`.
4. **Round 3 (Final Evaluation):** The revised solutions are evaluated through another round of blind ranking and aggregation, yielding final scores (`V^final`).
5. **Reward Computation:** Three distinct reward signals are calculated for each agent `i`:
* **Salient Reward (`r_i^sal`):** Directly equals the agent's final performance score (`V_i^final`).
* **Meta Reward (`r_i^meta`):** Measures how well the agent's personal preferences (`Pref_i`) aligned with the majority preference (`Maj`) across all pairwise comparisons in its final ranking (`R_i^final`). It's an average of indicator functions.
* **Diagnostic Reward (`r_i^diag`):** Quantifies the agent's "critique impact." It sums, over all agents `k` that agent `i` critiqued (set `T_i`), the positive improvement in `k`'s score from initial to final (`max(V_k^final - V_k^init, 0)`). This rewards agents for giving critiques that help others improve.
6. **Learning Loop:** These rewards are used for `Token-level credit assignment` and `Policy Updates`, enabling `Self-improvement via Self-play` by updating the shared policy `πθ`.
### Key Observations
* **Multi-Round Feedback:** The process is not a single evaluation but an iterative cycle of generation, evaluation, feedback, revision, and re-evaluation.
* **Dual Evaluation Pathways:** In Rounds 1 and 3, evaluation happens both through explicit ranking/aggregation (for scores) and through critique generation (for feedback).
* **Sophisticated Reward Structure:** The system doesn't just reward final performance (`r_i^sal`). It also rewards alignment with group judgment (`r_i^meta`) and, notably, the ability to constructively help other agents improve (`r_i^diag`).
* **Self-Contained Loop:** The entire process forms a closed loop where the policy updated by the rewards feeds back into the initial generation step, enabling continuous self-improvement.
* **Example Data:** The provided examples (`A1: 0.62, A2: 0.32` and `A1: 0.92, A2: 0.12`) suggest that scores can change significantly between rounds, and rankings can be re-ordered (e.g., `A4` rises to the top in the Round 3 example).
### Interpretation
This diagram outlines a sophisticated **multi-agent debate and self-play framework** designed to improve the quality and alignment of AI-generated solutions. The core Peircean investigative insight is that the system uses **social learning dynamics**—ranking, critique, and revision—to converge on better outcomes than any single agent could produce alone.
* **Purpose:** The framework aims to move beyond simple majority voting or single-model generation. It creates a competitive yet collaborative environment where agents are incentivized not only to be correct themselves but also to be good critics who elevate the group's performance.
* **Mechanism:** The three-round structure (Generate -> Critique/Revise -> Final Verdict) mimics human processes like peer review, academic debate, or iterative design. The `Bradley-Terry Aggregation` is a standard method for deriving a total ordering from pairwise comparisons, grounding the subjective rankings in a statistical model.
* **Significance of the Reward Structure:** The most innovative aspect is the **diagnostic reward (`r_i^diag`)**. It explicitly models and rewards the "teaching" or "critique" ability of an agent. An agent's success is tied not just to its own final score, but to how much it improved the scores of others through its feedback. This encourages the development of agents that are not only capable but also helpful and constructive, potentially leading to more robust and aligned collective intelligence.
* **Underlying Assumption:** The process assumes that through this structured interaction, the shared policy `πθ` will learn to generate solutions that are both high-quality (as measured by final ranking) and robust (having survived critique and revision), and that the agents will learn to provide more useful critiques over time. The "self-play" aspect means the system can generate its own training data and improvement signals without external human feedback after the initial setup.
DECODING INTELLIGENCE...