## Horizontal Bar Chart: Kimi-K2-Instruct Open-Ended Evaluation
### Overview
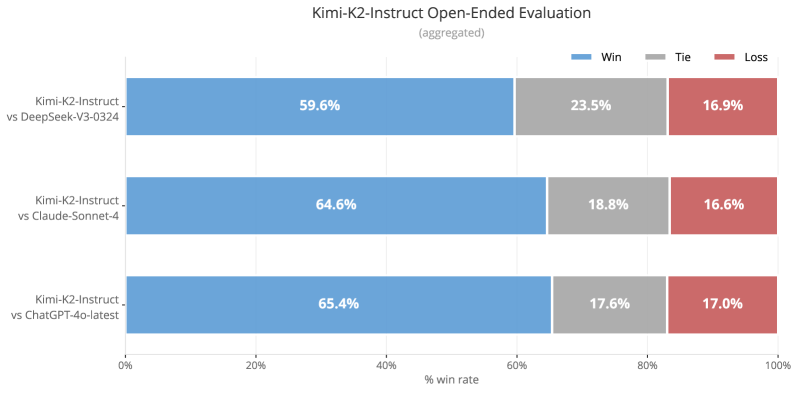
The image is a horizontal bar chart comparing the performance of Kimi-K2-Instruct against three other models: DeepSeek-V3-0324, Claude-Sonnet-4, and ChatGPT-4o-latest. The chart displays the win rate, tie rate, and loss rate for each comparison, aggregated across multiple evaluations.
### Components/Axes
* **Title:** Kimi-K2-Instruct Open-Ended Evaluation (aggregated)
* **X-axis:** % win rate, ranging from 0% to 100% in increments of 20%.
* **Y-axis:** Three categories representing the comparisons:
* Kimi-K2-Instruct vs DeepSeek-V3-0324
* Kimi-K2-Instruct vs Claude-Sonnet-4
* Kimi-K2-Instruct vs ChatGPT-4o-latest
* **Legend:** Located at the top-right of the chart.
* Blue: Win
* Gray: Tie
* Red: Loss
### Detailed Analysis
The chart presents the win, tie, and loss rates for Kimi-K2-Instruct against each of the other models. Each horizontal bar is segmented into three colored sections representing these rates.
* **Kimi-K2-Instruct vs DeepSeek-V3-0324:**
* Win (Blue): 59.6%
* Tie (Gray): 23.5%
* Loss (Red): 16.9%
* **Kimi-K2-Instruct vs Claude-Sonnet-4:**
* Win (Blue): 64.6%
* Tie (Gray): 18.8%
* Loss (Red): 16.6%
* **Kimi-K2-Instruct vs ChatGPT-4o-latest:**
* Win (Blue): 65.4%
* Tie (Gray): 17.6%
* Loss (Red): 17.0%
### Key Observations
* Kimi-K2-Instruct has the highest win rate against ChatGPT-4o-latest (65.4%) and the lowest against DeepSeek-V3-0324 (59.6%).
* The tie rate is highest against DeepSeek-V3-0324 (23.5%) and lowest against ChatGPT-4o-latest (17.6%).
* The loss rates are relatively similar across all three comparisons, ranging from 16.6% to 17.0%.
### Interpretation
The data suggests that Kimi-K2-Instruct performs best against ChatGPT-4o-latest in open-ended evaluations, achieving the highest win rate and lowest tie rate. Its performance against Claude-Sonnet-4 is also strong, with a win rate close to that of ChatGPT-4o-latest. While Kimi-K2-Instruct still wins the majority of the time against DeepSeek-V3-0324, it has a lower win rate and a higher tie rate compared to the other two models. The relatively consistent loss rates across all comparisons indicate a baseline level of failure, regardless of the opponent. Overall, Kimi-K2-Instruct demonstrates competitive performance in open-ended evaluations, particularly against ChatGPT-4o-latest and Claude-Sonnet-4.