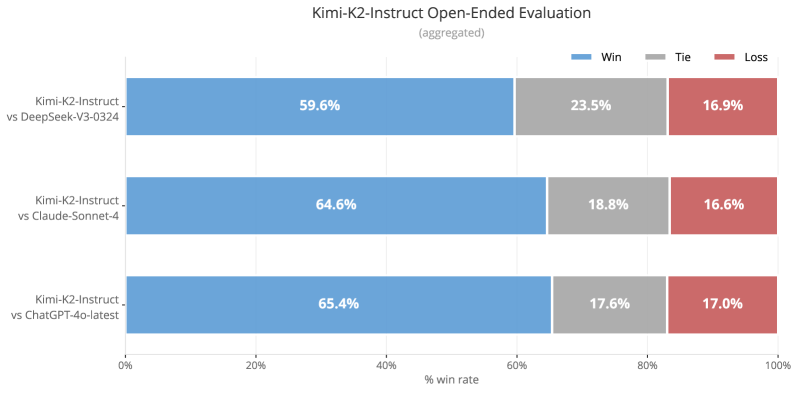
## Bar Chart: Kimi-K2-Instruct Open-Ended Evaluation (aggregated)
### Overview
The chart compares the performance of **Kimi-K2-Instruct** against three language models (DeepSeek-V3-0324, Claude-Sonnet-4, ChatGPT-4o-latest) in open-ended evaluations. Results are aggregated into three categories: **Win**, **Tie**, and **Loss**, represented by colored bars. Percentages are displayed atop each bar.
### Components/Axes
- **X-axis**: "% win rate" (0% to 100% in 20% increments).
- **Y-axis**: Three comparison groups:
1. Kimi-K2-Instruct vs DeepSeek-V3-0324
2. Kimi-K2-Instruct vs Claude-Sonnet-4
3. Kimi-K2-Instruct vs ChatGPT-4o-latest
- **Legend**:
- Blue = Win
- Gray = Tie
- Red = Loss
- **Bar Structure**: Each group contains three horizontally stacked bars (Win, Tie, Loss) with percentages labeled.
### Detailed Analysis
1. **Kimi-K2-Instruct vs DeepSeek-V3-0324**:
- Win: 59.6% (blue)
- Tie: 23.5% (gray)
- Loss: 16.9% (red)
2. **Kimi-K2-Instruct vs Claude-Sonnet-4**:
- Win: 64.6% (blue)
- Tie: 18.8% (gray)
- Loss: 16.6% (red)
3. **Kimi-K2-Instruct vs ChatGPT-4o-latest**:
- Win: 65.4% (blue)
- Tie: 17.6% (gray)
- Loss: 17.0% (red)
### Key Observations
- **Win Rates**: Kimi-K2-Instruct achieves the highest win rates across all comparisons, increasing from 59.6% (vs DeepSeek) to 65.4% (vs ChatGPT-4o-latest).
- **Tie Rates**: Decrease as opponent strength increases (23.5% → 17.6%), suggesting fewer inconclusive outcomes against stronger models.
- **Loss Rates**: Relatively stable (16.6–17.0%), indicating consistent performance even against advanced models.
### Interpretation
The data demonstrates that **Kimi-K2-Instruct** outperforms all three compared models in open-ended evaluations, with performance gains against stronger opponents (e.g., ChatGPT-4o-latest). The decline in tie rates suggests that Kimi’s interactions with advanced models result in more decisive outcomes (wins/losses) rather than ambiguous ties. The stable loss rates imply that when Kimi fails, it does so in closely contested scenarios, highlighting its robustness in competitive settings. This positions Kimi-K2-Instruct as a leading model in handling complex, open-ended tasks.