# Technical Document Extraction: Attention Forward Speed Benchmark
## 1. Header Information
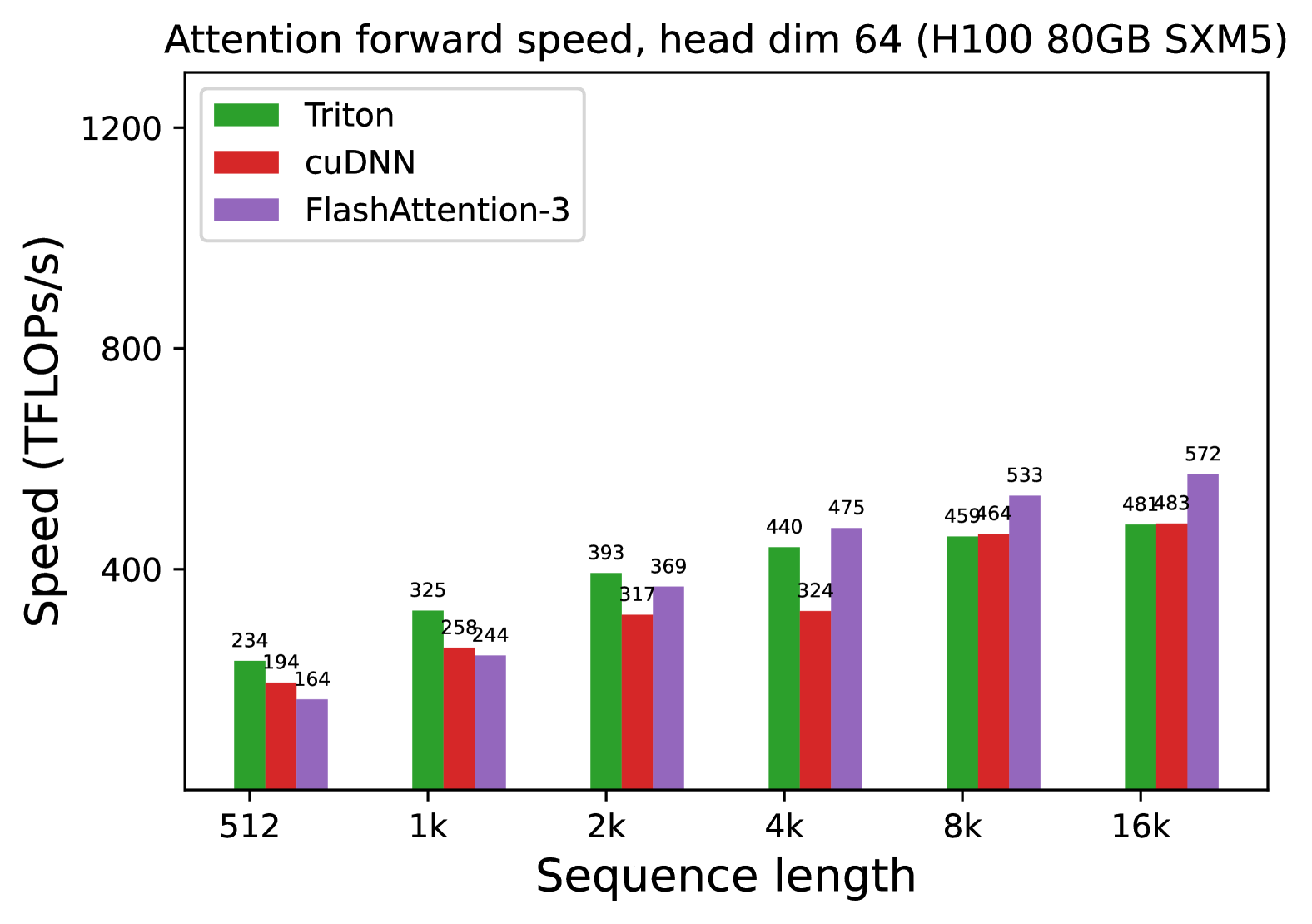
* **Title:** Attention forward speed, head dim 64 (H100 80GB SXM5)
* **Hardware Context:** NVIDIA H100 80GB SXM5 GPU.
* **Parameter Context:** Head dimension is fixed at 64.
## 2. Chart Metadata and Structure
* **Chart Type:** Grouped Bar Chart.
* **X-Axis (Independent Variable):** Sequence length.
* **Scale:** Categorical/Logarithmic progression (512, 1k, 2k, 4k, 8k, 16k).
* **Y-Axis (Dependent Variable):** Speed (TFLOPs/s).
* **Scale:** Linear, ranging from 0 to 1200, with major ticks at intervals of 400.
* **Legend:**
* **Green Bar:** Triton
* **Red Bar:** cuDNN
* **Purple Bar:** FlashAttention-3
## 3. Component Analysis and Trend Verification
### Triton (Green Bars)
* **Visual Trend:** Shows a consistent upward slope as sequence length increases, beginning to plateau slightly between 8k and 16k.
* **Performance:** It is the fastest implementation at the shortest sequence length (512) but is overtaken by FlashAttention-3 as the sequence length grows.
### cuDNN (Red Bars)
* **Visual Trend:** Shows a steady upward slope. It consistently performs lower than Triton across most sequence lengths but matches Triton's performance at the 16k mark.
* **Performance:** Generally the slowest or second-slowest implementation depending on the sequence length.
### FlashAttention-3 (Purple Bars)
* **Visual Trend:** Shows the steepest upward slope. While it starts as the slowest implementation at 512, it scales the most efficiently, overtaking cuDNN at 2k and Triton at 4k.
* **Performance:** Becomes the dominant implementation for long sequences (4k and above).
## 4. Data Table Reconstruction
The following table transcribes the numerical values labeled above each bar in the chart.
| Sequence Length | Triton (Green) [TFLOPs/s] | cuDNN (Red) [TFLOPs/s] | FlashAttention-3 (Purple) [TFLOPs/s] |
| :--- | :--- | :--- | :--- |
| **512** | 234 | 194 | 164 |
| **1k** | 325 | 258 | 244 |
| **2k** | 393 | 317 | 369 |
| **4k** | 440 | 324 | 475 |
| **8k** | 459 | 464 | 533 |
| **16k** | 481 | 483 | 572 |
## 5. Summary of Findings
The benchmark demonstrates that while **Triton** is optimized for shorter sequence lengths (under 1k), **FlashAttention-3** exhibits superior scaling properties on H100 hardware. By the 16k sequence length, FlashAttention-3 reaches **572 TFLOPs/s**, outperforming Triton (481 TFLOPs/s) and cuDNN (483 TFLOPs/s) by approximately 18-19%.