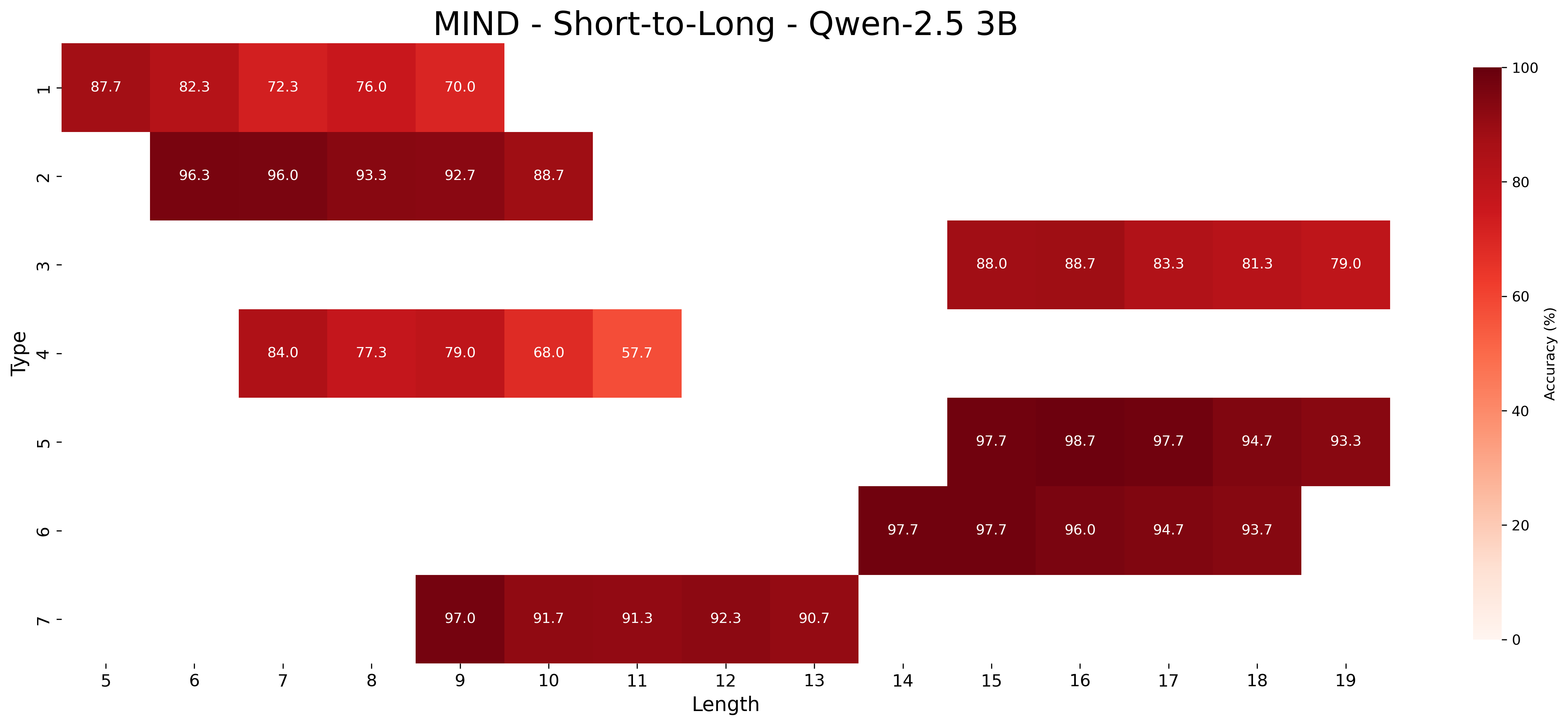
## Heatmap: MIND - Short-to-Long - Qwen-2.5 3B
### Overview
This image is a heatmap visualizing the accuracy performance of the "Qwen-2.5 3B" model on the "MIND" dataset, specifically for a "Short-to-Long" task. The chart plots model accuracy (%) against two categorical variables: "Type" (vertical axis) and "Length" (horizontal axis). The data is presented as a grid of colored cells, where the color intensity represents the accuracy value, with a corresponding color bar legend on the right.
### Components/Axes
* **Title:** "MIND - Short-to-Long - Qwen-2.5 3B" (Top center).
* **Vertical Axis (Y-axis):**
* **Label:** "Type" (Rotated 90 degrees, left side).
* **Categories/Ticks:** 1, 2, 3, 4, 5, 6, 7 (Listed from top to bottom).
* **Horizontal Axis (X-axis):**
* **Label:** "Length" (Bottom center).
* **Categories/Ticks:** 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19 (Listed from left to right).
* **Legend/Color Bar:**
* **Position:** Right side of the chart.
* **Label:** "Accuracy (%)" (Rotated 90 degrees, next to the bar).
* **Scale:** A continuous gradient from light peach/white (0%) to dark red (100%).
* **Tick Marks:** 0, 20, 40, 60, 80, 100.
### Detailed Analysis
The heatmap is sparse, with data points only for specific combinations of Type and Length. Each cell contains a numerical accuracy value. Below is the extracted data, organized by Type (row) and corresponding Length (column):
**Type 1 (Top row):**
* Length 5: 87.7%
* Length 6: 82.3%
* Length 7: 72.3%
* Length 8: 76.0%
* Length 9: 70.0%
**Type 2:**
* Length 6: 96.3%
* Length 7: 96.0%
* Length 8: 93.3%
* Length 9: 92.7%
* Length 10: 88.7%
**Type 3:**
* Length 15: 88.0%
* Length 16: 88.7%
* Length 17: 83.3%
* Length 18: 81.3%
* Length 19: 79.0%
**Type 4:**
* Length 7: 84.0%
* Length 8: 77.3%
* Length 9: 79.0%
* Length 10: 68.0%
* Length 11: 57.7%
**Type 5:**
* Length 15: 97.7%
* Length 16: 98.7%
* Length 17: 97.7%
* Length 18: 94.7%
* Length 19: 93.3%
**Type 6:**
* Length 14: 97.7%
* Length 15: 97.7%
* Length 16: 96.0%
* Length 17: 94.7%
* Length 18: 93.7%
**Type 7 (Bottom row):**
* Length 9: 97.0%
* Length 10: 91.7%
* Length 11: 91.3%
* Length 12: 92.3%
* Length 13: 90.7%
### Key Observations
1. **Performance Variability by Type:** There is significant variation in accuracy across different "Types." Types 2, 5, 6, and 7 consistently show very high accuracy (mostly >90%), indicated by the darkest red cells. Type 4 shows the lowest performance, with accuracy dropping to 57.7% at Length 11.
2. **Performance Trend with Length:** For most Types where data is available across a range of lengths, there is a general trend of **decreasing accuracy as Length increases**. This is visible as a color gradient from darker to lighter red moving left to right within a Type's row (e.g., Type 1: 87.7% → 70.0%; Type 4: 84.0% → 57.7%).
3. **Data Sparsity:** The heatmap is not fully populated. Each Type has data for only a contiguous block of 5 consecutive Lengths, and these blocks are offset from each other. For example, Type 1 covers lengths 5-9, Type 2 covers 6-10, Type 3 covers 15-19, etc. This suggests the evaluation was performed on specific, non-overlapping length intervals for each task type.
4. **Outliers:** Type 4 at Length 11 (57.7%) is a notable low point. Type 5 at Length 16 (98.7%) is the highest recorded accuracy in the chart.
### Interpretation
This heatmap provides a diagnostic view of the Qwen-2.5 3B model's capabilities on the MIND benchmark. The "Short-to-Long" context suggests the task involves processing or generating information where sequence length is a key variable.
* **Model Strengths:** The model excels (accuracy >90%) on several task Types (2, 5, 6, 7) across their evaluated length ranges. This indicates robust performance on those specific sub-tasks within the MIND dataset.
* **Model Weaknesses & Length Sensitivity:** The clear downward trend in accuracy with increasing length for Types 1 and 4 reveals a key limitation: the model's performance degrades as the sequence length grows for these task categories. Type 4 is particularly sensitive, showing a steep decline. This could point to challenges in maintaining coherence, attention, or reasoning over longer contexts for those specific task formulations.
* **Task-Specific Performance:** The stark difference in performance between Types (e.g., Type 2 vs. Type 4) implies that the model's effectiveness is highly dependent on the nature of the task ("Type"). The MIND benchmark likely contains diverse sub-tasks, and this model has an uneven proficiency across them.
* **Experimental Design:** The offset, non-overlapping length windows for each Type suggest a controlled experimental setup designed to isolate the effect of length within specific task categories, rather than testing all Types across all lengths. This is efficient but means direct comparison of, for example, Type 1 at Length 15 is not possible from this chart.
In summary, the data demonstrates that the Qwen-2.5 3B model has strong but task-dependent performance on the MIND benchmark, with a notable vulnerability to performance degradation on certain tasks as sequence length increases.